Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это важно
Надстройка "Кластеры больших данных Microsoft SQL Server 2019" будет прекращена. Поддержка кластеров больших данных SQL Server 2019 завершится 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на этой платформе, а программное обеспечение будет продолжать поддерживаться с помощью накопительных обновлений для SQL Server до этого времени. Для получения дополнительной информации см. запись блога об объявлении и параметры работы с большими данными на платформе Microsoft SQL Server.
Узнайте, как использовать средства Spark и Hive для Visual Studio Code для создания и отправки скриптов PySpark для Apache Spark, сначала описано, как установить средства Spark и Hive в Visual Studio Code, а затем мы рассмотрим, как отправить задания в Spark.
Средства Spark и Hive можно установить на платформах, поддерживаемых Visual Studio Code, которые включают Windows, Linux и macOS. Ниже приведены предварительные требования для разных платформ.
Предпосылки
Для выполнения действий, описанных в этой статье, необходимо следующее:
- Кластер больших данных SQL Server. См. статью "Кластеры больших данных SQL Server".
- Visual Studio Code.
- Python и расширение Python в Visual Studio Code.
- Mono. Mono требуется только для Linux и macOS.
- Настройте интерактивную среду PySpark для Visual Studio Code.
- Локальный каталог с именем SQLBDCexample. В этой статье используется C:\SQLBDC\SQLBDCexample.
Установка Spark & Hive Tools
После завершения предварительных требований можно установить средства Spark и Hive для Visual Studio Code. Выполните следующие действия, чтобы установить средства Spark и Hive:
Откройте Visual Studio Code.
В строке меню выберите Вид>Расширения.
В поле поиска введите Spark & Hive.
Выберите Spark и Hive Tools, опубликованные корпорацией Майкрософт, в результатах поиска и нажмите кнопку "Установить".

Перезагрузите при необходимости.
Открытие рабочей папки
Выполните следующие действия, чтобы открыть рабочую папку и создать файл в Visual Studio Code:
В строке меню перейдите к Файл>Открыть папку...>C:\SQLBDC\SQLBDCexample, а затем нажмите кнопку Выбрать папку. Папка отображается в представлении проводника слева.
В представлении обозревателя выберите папку SQLBDCexample, а затем значок "Создать файл " рядом с рабочей папкой.

Назовите новый файл расширением
.pyфайла (скрипт Spark). В этом примере используется HelloWorld.py.Скопируйте и вставьте в файл скрипта следующий код:
import sys from operator import add from pyspark.sql import SparkSession, Row spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() data = [Row(col1='pyspark and spark', col2=1), Row(col1='pyspark', col2=2), Row(col1='spark vs hadoop', col2=2), Row(col1='spark', col2=2), Row(col1='hadoop', col2=2)] df = spark.createDataFrame(data) lines = df.rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) output = counters.collect() sortedCollection = sorted(output, key = lambda r: r[1], reverse = True) for (word, count) in sortedCollection: print("%s: %i" % (word, count))
Связывание кластера больших данных SQL Server
Прежде чем отправлять скрипты в кластеры из Visual Studio Code, необходимо связать кластер больших данных SQL Server.
В строке меню перейдите к представлению>палитры команд..., а затем введите Spark /Hive: связывание кластера.

Выберите связанный тип кластера SQL Server Big Data.
Введите конечную точку больших данных SQL Server.
Введите имя пользователя кластера больших данных SQL Server.
Введите пароль для администратора пользователя.
Задайте отображаемое имя кластера больших данных (необязательно).
Перечислите кластеры, просмотрите представление OUTPUT для проверки.
список кластеров
В строке меню перейдите к представлению>палитры команд..., а затем введите Spark / Hive: List Cluster.
Просмотрите представление OUTPUT. В представлении будут показаны ваши связанные кластеры.

Настройка кластера по умолчанию
Re-Open папка SQLBDCexample, созданная ранее, если закрыта.
Выберите файл , HelloWorld.py созданный ранее , и он откроется в редакторе скриптов.
Свяжите кластер, если вы еще не сделали этого.
Щелкните правой кнопкой мыши редактор скриптов и выберите Spark / Hive: Задать кластер по умолчанию.
Выберите кластер в качестве используемого по умолчанию для текущего файла скрипта. Средства автоматически обновляют файл конфигурации .VSCode\settings.json.

Отправка интерактивных запросов PySpark
Интерактивные запросы PySpark можно отправить, выполнив следующие действия:
Повторно откройте папку SQLBDCexample, созданную ранее, если она закрыта.
Выберите файл , HelloWorld.py созданный ранее , и он откроется в редакторе скриптов.
Свяжите кластер, если вы еще не сделали этого.
Выберите весь код и щелкните правой кнопкой мыши редактор скриптов, выберите Spark: PySpark Interactive , чтобы отправить запрос, или используйте сочетание клавиш CTRL+ALT+I.

Выберите кластер, если вы не указали кластер по умолчанию. Через несколько минут интерактивные результаты Python отображаются на новой вкладке. Средства также позволяют отправлять блок кода вместо всего файла скрипта с помощью контекстного меню.
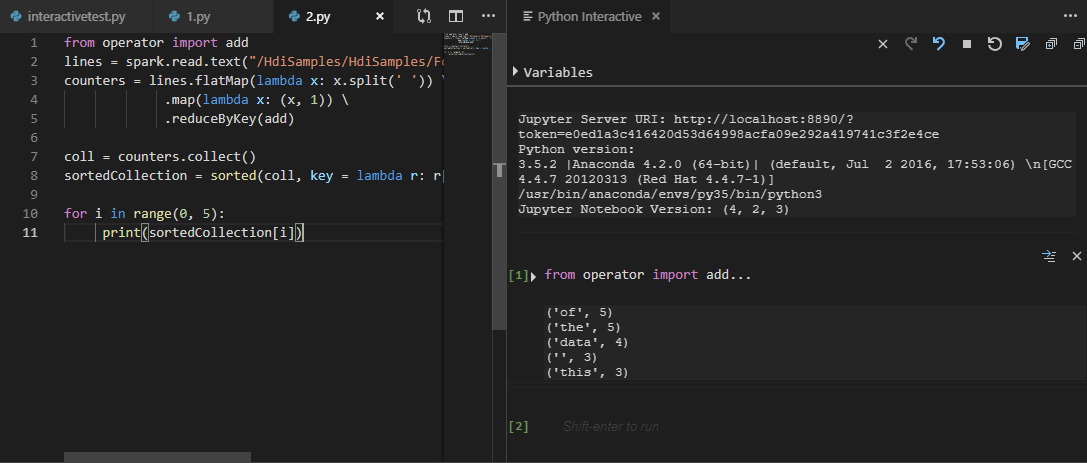
Введите "%%info", а затем нажмите клавиши SHIFT+ВВОД , чтобы просмотреть сведения о задании. (Необязательно)

Замечание
Когда расширение Python отключено в настройках (по умолчанию оно включено), результаты отправленных взаимодействий pyspark будут использовать старое окно.
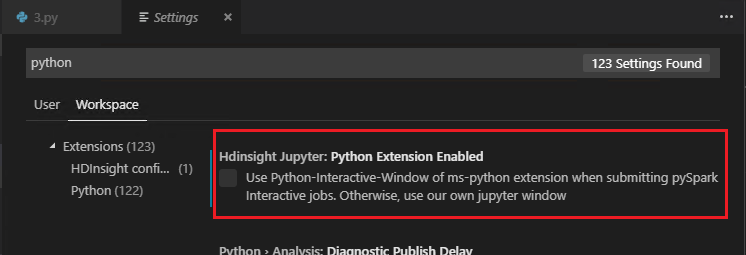
Отправка пакетного задания PySpark
Повторно откройте папку SQLBDCexample, созданную ранее, если она закрыта.
Выберите файл , HelloWorld.py созданный ранее , и он откроется в редакторе скриптов.
Свяжите кластер, если вы еще не сделали этого.
Щелкните правой кнопкой мыши редактор скриптов и выберите Spark: PySpark Batch или используйте сочетание клавиш CTRL+ALT+H.
Выберите кластер, если вы не указали кластер по умолчанию. После отправки задания Python журналы отправки отображаются в окне вывода в Visual Studio Code. Также отображаются URL-адрес пользовательского интерфейса Spark и URL-адрес пользовательского интерфейса Yarn . Вы можете открыть этот URL-адрес в браузере для отслеживания состояния задания.

Конфигурация Apache Livy
Конфигурация Apache Livy поддерживается, ее можно задать в разделе .VSCode\settings.js в рабочей папке. Сейчас конфигурация Livy поддерживает только скрипт Python. Дополнительные сведения см. в статье Livy README.
Активация конфигурации Livy
Метод 1
- В строке меню выберите Файл>Настройки>Параметры.
- В текстовом поле параметров поиска введите HDInsight Job Submission: Livy Conf.
- Выберите Изменить в settings.json для соответствующего результата поиска.
Метод 2
Отправьте файл и обратите внимание, что папка .vscode добавляется автоматически в рабочую папку. Конфигурацию Livy можно найти, выбрав settings.json в разделе .vscode.
Параметры проекта:

Замечание
Для настроек driverMemory и executorMemory задайте значение с единицей, например 1 ГБ или 1024 МБ.
Поддерживаемые конфигурации Livy
POST /batches
текст запроса
| имя | описание | тип |
|---|---|---|
| файл | Файл, содержащий приложение для выполнения | путь (обязательный) |
| proxyUser | Пользователь, олицетворяемый при выполнении задания | струна |
| имя класса | Класс main приложения в Java/Spark | струна |
| args | Аргументы командной строки для приложения | список строк |
| Банки | Jars для использования в этом сеансе | Список строк |
| pyFiles | Файлы Python для использования в этом сеансе | Список строк |
| Файлы | файлы, используемые в этом сеансе | Список строк |
| память драйвера | Объем памяти, используемой для процесса драйвера | струна |
| driverCores | Число ядер, используемых для процесса драйвера | инт |
| исполнителяMemory | Объем памяти для каждого процесса исполнителя | струна |
| executorCores | Число ядер, используемых для каждого исполнителя | инт |
| количество исполнителей | Количество исполнителей для запуска этого сеанса | инт |
| архив | Архивы, используемые в этом сеансе | Список строк |
| очередь | Имя очереди YARN, в которую отправлена | струна |
| имя | Имя этого сеанса | струна |
| конф | Свойства конфигурации Spark | Сопоставление key=val |
| :- | :- | :- |
Содержимое ответа
Созданный пакетный объект.
| имя | описание | тип |
|---|---|---|
| идентификатор | Идентификатор сеанса | инт |
| appId (идентификатор приложения) | Идентификатор приложения этого сеанса | Струна |
| appInfo | Подробные сведения о приложении | Сопоставление key=val |
| журнал | Строки журнала | список строк |
| государство | Состояние пакетной службы | струна |
| :- | :- | :- |
Замечание
Назначенная конфигурация Livy будет отображаться в области вывода при отправке скрипта.
Дополнительные функции
Spark и Hive для Visual Studio Code поддерживает следующие функции:
Автозавершение IntelliSense. Появляются предложения для ключевых слов, методов, переменных и т. д. Различные значки представляют различные типы объектов.

Маркер ошибок IntelliSense. Языковая служба подчеркивает ошибки редактирования скрипта Hive.
Выделение синтаксиса. Языковая служба использует различные цвета, чтобы различать переменные, ключевые слова, тип данных, функции и многое другое.

Удаление связи кластера
В строке меню перейдите к представлению>палитры команд..., а затем введите Spark / Hive: отмените связь с кластером.
Выберите кластер для отмены связи.
Просмотрите представление OUTPUT для проверки.
Дальнейшие шаги
Дополнительные сведения о кластере больших данных SQL Server и связанных сценариях см. в кластерах больших данных SQL Server.