Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Tip
Power BI Dataflow 1-го поколения теперь находится в устаревшем состоянии и не получит новых инвестиций в функции. Для премиум-клиентов с доступом к Fabric, Dataflow Gen2 является рекомендуемым решением, предлагая улучшения в производительности, масштабируемости, надежности, функциональности и встроенном ИИ. Клиенты Pro/PPU могут продолжать использовать Gen1, так как руководства по Gen2 для этих сценариев всё ещё разрабатываются. См. статью Обновление с Dataflow Gen1 до Dataflow Gen2 для получения инструкций по обновлению.
Рабочие нагрузки потока данных можно создать в подписке Power BI Premium. Power BI использует концепцию нагрузок для описания содержимого класса Premium. Рабочие нагрузки включают наборы данных, отчеты с разбивкой на страницы, потоки данных и ИИ. Рабочая нагрузка потоков данных позволяет использовать самостоятельную подготовку данных для приема, преобразования, интеграции и обогащения данных. Потоки данных Power BI Premium управляются на портале администрирования.
В следующих разделах описывается, как включить потоки данных в организации, как уточнить их параметры в емкости Premium и рекомендации по общему использованию.
Включение потоков данных в Power BI Premium
Первое требование использования потоков данных в подписке Power BI Premium — включение создания и использования потоков данных для вашей организации. На портале администрирования выберите "Параметры клиента" и переключите ползунок в разделе "Параметры потока данных" на "Включено", как показано на следующем рисунке.

После включения рабочей нагрузки потоков данных она настроена с параметрами по умолчанию. Вы можете настроить эти параметры, как вам угодно. Далее мы описываем, где находятся эти параметры, описываем каждый из них и помогаем вам понять, когда может потребоваться изменить значения для оптимизации производительности потока данных.
Уточнение параметров потока данных в Premium
После включения потоков данных можно использовать портал администрирования для изменения или уточнения способа создания потоков данных и использования ресурсов в подписке Power BI Premium. Power BI Premium не требует изменения параметров памяти. Память в Power BI Premium автоматически управляет базовой системой. Ниже показано, как настроить параметры потока данных.
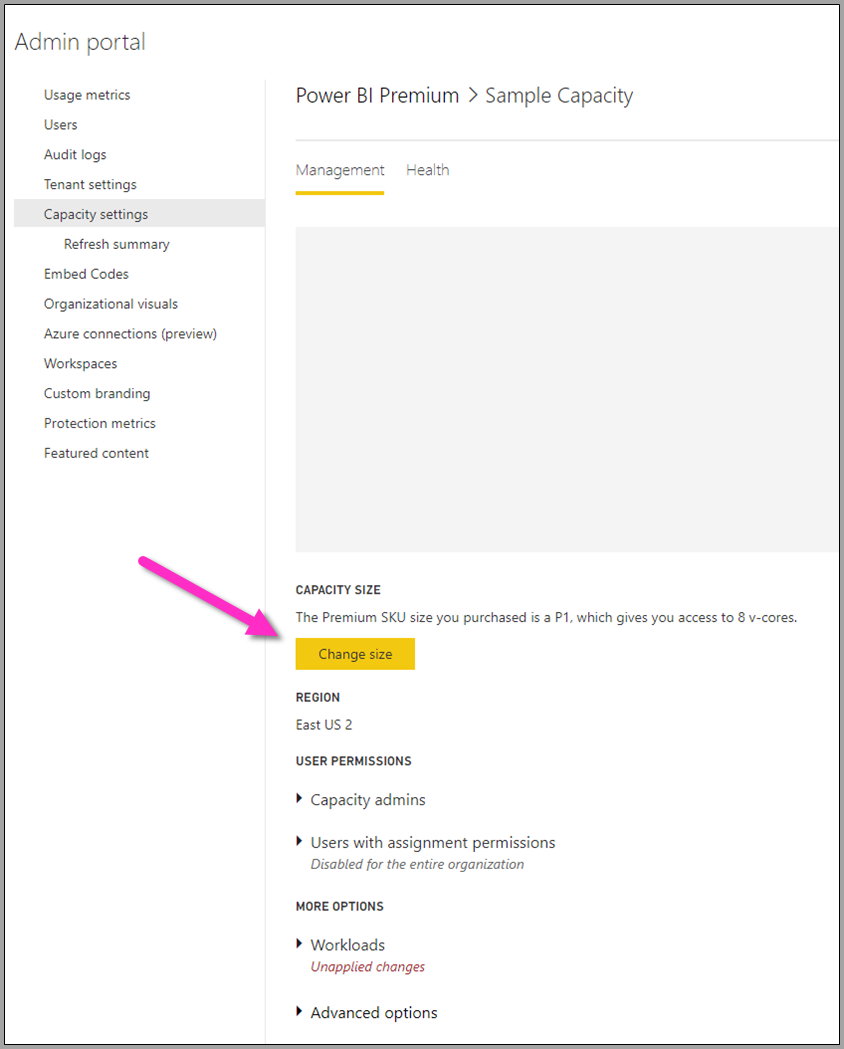
На портале администратора выберите параметры арендатора, чтобы отобразить список всех созданных ресурсов. Выберите емкость, чтобы управлять ее настройками.
Емкость Power BI Premium отражает ресурсы, доступные для потоков данных. Размер емкости можно изменить, нажав кнопку "Изменить размер ", как показано на следующем рисунке.
Номера SKU емкости Premium — увеличение масштаба оборудования
Рабочие нагрузки Power BI Premium используют виртуальные ядра для быстрого выполнения запросов в различных типах рабочих нагрузок. Емкости и SKU включают диаграмму, иллюстрирующую текущие спецификации для каждого из доступных предложений по рабочей нагрузке. Емкости A3 и выше могут воспользоваться преимуществами вычислительного ядра, поэтому, когда вы хотите использовать расширенный вычислительный модуль, запустите его.
Расширенная подсистема вычислений — возможность повышения производительности
Расширенный вычислительный модуль — это подсистема , которая может ускорить запросы. Power BI использует подсистему вычислений для обработки запросов и операций обновления. Расширенный вычислительный механизм — это улучшение по сравнению со стандартным механизмом и работает путем загрузки данных в кэш SQL и использования SQL для ускорения преобразования таблиц, операций обновления и включения подключения DirectQuery. Если настроено On или Optimized для вычислительных сущностей, если бизнес-логика позволяет ему, Power BI использует SQL для ускорения производительности. Наличие подсистемы On также обеспечивает подключение DirectQuery. Убедитесь, что использование потока данных с помощью улучшенного вычислительного движка происходит должным образом. Пользователи могут настроить расширенный вычислительный механизм для каждого потока данных в режиме включен, оптимизирован или выключен.
Примечание.
Расширенный вычислительный модуль еще недоступен во всех регионах.
Руководство по общим сценариям
В этом разделе приведены рекомендации по общим сценариям при использовании рабочих нагрузок потока данных с Power BI Premium.
Время медленного обновления
Время медленного обновления обычно является проблемой параллелизма. Рассмотрите следующие параметры в указанном порядке:
Ключевым понятием медленного времени обновления является характер подготовки данных. Каждый раз, когда вы можете оптимизировать время медленного обновления, используя преимущества источника данных, фактически выполняя подготовку и выполнение логики запроса заранее, это необходимо сделать. В частности, при использовании реляционной базы данных, например SQL в качестве источника, проверьте, можно ли запустить исходный запрос в источнике и использовать этот исходный запрос для исходного потока данных извлечения для источника данных. Если вы не можете использовать собственный запрос в исходной системе, выполните операции, которые подсистема потоков данных может сложить в источник данных.
Оцените распределение времени обновления для одинаковой емкости. Операции обновления — это процесс, требующий значительных вычислений. Используя аналогию нашего ресторана, распространение времени обновления сродни ограничению количества гостей в вашем ресторане. Точно так же, как рестораны расписывают время для гостей и планируют загрузку, вы также захотите рассмотреть операции обновления в те периоды, когда использование не достигает максимума. Это может значительно помочь уменьшить нагрузку на пропускную способность.
Если действия, описанные в этом разделе, не обеспечивают нужную степень параллелизма, рассмотрите возможность повышения производительности до более высокого SKU. Затем выполните предыдущие шаги в этой последовательности еще раз.
Использование подсистемы вычислений для повышения производительности
Выполните следующие действия, чтобы рабочие нагрузки могли активировать подсистему вычислений и всегда повысить производительность:
Для вычисляемых и связанных сущностей в одной рабочей области:
Для загрузки сосредоточьтесь на максимально быстрой загрузке данных в хранилище, используйте фильтры только если они уменьшают общий размер набора данных. Рекомендуется сохранить логику преобразования отдельно от этого шага и разрешить подсистеме сосредоточиться на первоначальном сборе ингредиентов. Затем отделите преобразование и бизнес-логику в отдельном потоке данных в той же рабочей области с помощью связанных или вычисляемых сущностей; это позволяет движку активировать и ускорить вычисления. Ваша логика должна быть подготовлена отдельно, прежде чем она сможет воспользоваться преимуществами вычислительной подсистемы.
Убедитесь, что вы выполняете операции свёртки, такие как слияния, соединения, преобразования и другие.
Создание потоков данных в рамках опубликованных рекомендаций и ограничений.
Вы также можете использовать DirectQuery.
Подсистема вычислений включена, но производительность замедляется
Выполните следующие действия при изучении сценариев, в которых подсистема вычислений включена, но вы видите более низкую производительность:
Ограничить вычисляемые и связанные сущности, которые существуют в рабочей области.
При первоначальном обновлении с включенным вычислительным движком данные записываются в озере данных и кэше. Это двойная запись означает, что процесс обновления замедляется.
Если у вас есть связывание потока данных с несколькими потоками данных, убедитесь, что вы планируете обновление исходных потоков данных, чтобы они не обновлялись одновременно.
Связанный контент
Дополнительные сведения о потоках данных и Power BI см. в следующих статьях.
- Введение в потоки данных и самостоятельную подготовку данных
- Создание потока данных
- Настройка и использование потока данных
- Настройка хранилища потока данных для использования Azure Data Lake 2-го поколения
- Планирование реализации Power BI — интеграция с другими службами
- Рекомендации и ограничения, касающиеся потоков данных