Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Применимо к: SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
Перекрытие запросов — это конфигурация системы табличного режима, которая может повысить производительность выполнения запросов в сценариях высокой параллельности. По умолчанию табличный механизм служб Analysis Services работает в режиме "первый пришёл — первый вышел" (FIFO) в отношении использования ЦП. Например, если получен один ресурсоемкий и, возможно, медленный запрос движка хранения, а затем следуют два других быстрых запроса, быстрые запросы могут быть заблокированы, ожидая завершения ресурсоемкого запроса. Это поведение показано на следующей схеме, в которой показаны Q1, Q2 и Q3 в качестве соответствующих запросов, их продолжительности и времени ЦП.

Переплетение запросов с учетом приоритета коротких запросов позволяет параллельным запросам совместно использовать ресурсы ЦП, что означает, что быстрые запросы не блокируются медленными запросами. Время выполнения всех трех запросов по-прежнему одинаково, но в нашем примере Q2 и Q3 не блокируются до конца. Предпочтение к коротким запросам означает, что им, на основании объема ЦП, который каждый из них уже использовал к определенному моменту времени, может выделяться более высокая доля ресурсов по сравнению с длительными запросами. На следующей схеме запросы Q2 и Q3 считаются быстрыми и выделены больше ЦП, чем Q1.
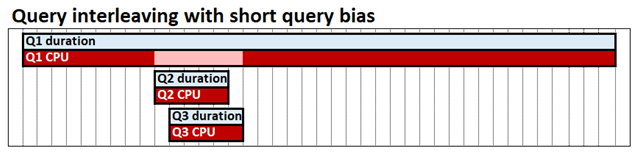
Переключение запросов не влияет на производительность запросов, выполняемых в изоляции; Один запрос по-прежнему может использовать столько ЦП, сколько это делает с моделью FIFO.
Важные замечания
Прежде чем определить, подходит ли чередование запросов для вашего сценария, помните следующее:
- Переключение запросов применяется только для моделей импорта. Это не влияет на модели DirectQuery.
- Переключение запросов учитывает только ресурсы ЦП, потребляемые запросами подсистемы хранилища VertiPaq. Он не применяется к операциям движка формул.
- Один запрос DAX может привести к нескольким запросам подсистемы хранилища VertiPaq. Запрос DAX считается быстрым или медленным в зависимости от ресурсов ЦП, потребляемых запросами, выполняемыми ядром хранилища. Запрос DAX — это единица измерения.
- Операции обновления по умолчанию защищены от перемежения запросов. Длительные операции обновления классифицируются иначе, чем длительные запросы.
Настройка
Чтобы настроить чередование запросов, задайте свойство Threadpool\SchedulingBehavior . Это свойство можно указать со следующими значениями:
| Ценность | Description |
|---|---|
| -1 | Automatic. Модуль выберет тип очереди. |
| 0 (по умолчанию для SSAS 2019) | Первый пришёл, первый ушёл (FIFO) |
| 1 | Предвзятость коротких запросов. Движок постепенно регулирует долго выполняющиеся запросы в условиях повышенной нагрузки, при этом приоритет отдается быстрым запросам. |
| 3 (по умолчанию для Azure AS, Power BI, SSAS 2022 и более поздних версий) | Предвзятость коротких запросов с быстрой отменой. Улучшает время отклика на пользовательские запросы в сценариях с высокой степенью параллельности. Применяется только к Azure AS, Power BI, SSAS 2022 и более поздним версиям. |
В настоящее время свойство SchedulingBehavior можно задать только с помощью XMLA. В SQL Server Management Studio следующий фрагмент XMLA задает для свойства SchedulingBehavior значение 1, предвзятость коротких запросов.
<Alter AllowCreate="true" ObjectExpansion="ObjectProperties" xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object />
<ObjectDefinition>
<Server xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ddl2="http://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="http://schemas.microsoft.com/analysisservices/2003/engine/2/2" xmlns:ddl100_100="http://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="http://schemas.microsoft.com/analysisservices/2010/engine/200" xmlns:ddl200_200="http://schemas.microsoft.com/analysisservices/2010/engine/200/200" xmlns:ddl300="http://schemas.microsoft.com/analysisservices/2011/engine/300" xmlns:ddl300_300="http://schemas.microsoft.com/analysisservices/2011/engine/300/300" xmlns:ddl400="http://schemas.microsoft.com/analysisservices/2012/engine/400" xmlns:ddl400_400="http://schemas.microsoft.com/analysisservices/2012/engine/400/400" xmlns:ddl500="http://schemas.microsoft.com/analysisservices/2013/engine/500" xmlns:ddl500_500="http://schemas.microsoft.com/analysisservices/2013/engine/500/500">
<ID>myserver</ID>
<Name>myserver</Name>
<ServerProperties>
<ServerProperty>
<Name>ThreadPool\SchedulingBehavior</Name>
<Value>1</Value>
</ServerProperty>
</ServerProperties>
</Server>
</ObjectDefinition>
</Alter>
Это важно
Требуется перезапуск экземпляра сервера. В Службах Azure Analysis Services необходимо приостановить и возобновить работу сервера, эффективно перезагрузив его.
Дополнительные свойства
В большинстве случаев SchedulingBehavior является единственным свойством, которое необходимо задать. Следующие дополнительные свойства имеют значения по умолчанию, которые должны работать в большинстве сценариев с короткой предвзятостью запросов, однако при необходимости их можно изменить. Следующие свойства не оказывают эффекта, если не включено чередование запросов через установку свойства SchedulingBehavior.
ReservedComputeForFastQueries — задает количество зарезервированных логических ядер для быстрых запросов. Все запросы считаются быстрыми, пока они не замедлятся, потому что они использовали определенный объем процессора (ЦП). ReservedComputeForFastQueries — целое число от 0 до 100. Значение по умолчанию — 75.
Единица измерения для ReservedComputeForFastQueries — это процент ядер. Например, значение 80 на сервере с 20 ядрами пытается зарезервировать 16 ядер для быстрых запросов (в то время как операции обновления не выполняются). ReservedComputeForFastQueries округляет до ближайшего целого числа ядер. Рекомендуется не задать это значение свойства ниже 50. Это связано с тем, что быстрые запросы могут быть лишены приоритета, что противоречит общей концепции функции.
DecayIntervalCPUTime — целое число, представляющее процессорное время в миллисекундах, которое запрос использует до распада. Если система испытывает нагрузку на ЦП, уменьшенные запросы обрабатываются оставшимися ядрами, которые не зарезервированы для быстрых запросов. Значение по умолчанию — 60 000. Это составляет 1 минуту времени работы ЦП, а не прошедшее время по календарю.
ReservedComputeForProcessing — задает количество зарезервированных логических ядер для каждой операции обработки (обновления данных). Значение свойства представляет собой целое число от 0 до 100 со значением по умолчанию 75. Значение представляет процент ядер, определенных свойством ReservedComputeForFastQueries. Значение 0 (ноль) означает, что операции обработки подчиняются той же логике чередования запросов, что и для самих запросов, поэтому могут распадаться.
Хотя операции обработки не выполняются, ReservedComputeForProcessing не действует. Например, со значением 80, ReservedComputeForFastQueries на сервере с 20 ядрами резервирует 16 ядер для быстрых запросов. При значении 75 ReservedComputeForProcessing резервирует 12 из 16 ядер для операций обновления, оставляя 4 для быстрых запросов, пока операции обработки выполняются и потребляют ЦП. Как описано в разделе «Устаревшие запросы» ниже, оставшиеся 4 ядра (не зарезервированы для быстрых запросов или операций обработки) будут по-прежнему использоваться для быстрых запросов и обработки в случае простоя.
Эти дополнительные свойства находятся в узле свойств ResourceGovernance . В SQL Server Management Studio следующий пример фрагмента XMLA задает свойству DecayIntervalCPUTime значение ниже по умолчанию:
<Alter AllowCreate="true" ObjectExpansion="ObjectProperties" xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object />
<ObjectDefinition>
<Server xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ddl2="http://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="http://schemas.microsoft.com/analysisservices/2003/engine/2/2" xmlns:ddl100_100="http://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="http://schemas.microsoft.com/analysisservices/2010/engine/200" xmlns:ddl200_200="http://schemas.microsoft.com/analysisservices/2010/engine/200/200" xmlns:ddl300="http://schemas.microsoft.com/analysisservices/2011/engine/300" xmlns:ddl300_300="http://schemas.microsoft.com/analysisservices/2011/engine/300/300" xmlns:ddl400="http://schemas.microsoft.com/analysisservices/2012/engine/400" xmlns:ddl400_400="http://schemas.microsoft.com/analysisservices/2012/engine/400/400" xmlns:ddl500="http://schemas.microsoft.com/analysisservices/2013/engine/500" xmlns:ddl500_500="http://schemas.microsoft.com/analysisservices/2013/engine/500/500">
<ID>myserver</ID>
<Name>myserver</Name>
<ServerProperties>
<ServerProperty>
<Name>ResourceGovernance\DecayIntervalCPUTime</Name>
<Value>15000</Value>
</ServerProperty>
</ServerProperties>
</Server>
</ObjectDefinition>
</Alter>
Устаревшие запросы
Ограничения, описанные в этом разделе, применяются только в том случае, если система находится под давлением ЦП. Например, один запрос, если он является единственным запущенным в системе в определенное время, может использовать все доступные ядра независимо от того, был ли он разложен или нет.
Для каждого запроса может потребоваться множество заданий ядра хранилища. Когда ядро в пуле для протухших запросов становится доступным, планировщик проверяет самый старый из выполняющихся запросов на основе прошедшего календарного времени, чтобы узнать, уже ли оно использовало свое максимальное распределение ядра (MCE). Если нет, выполняется следующее задание. Если да, то оценивается следующий по порядку самый старый запрос. Определение запроса MCE зависит от того, сколько интервалов распада он уже использовал. Для каждого используемого интервала распада mcE уменьшается на основе алгоритма, показанного в таблице ниже. Это продолжается до тех пор, пока запрос не завершится, либо истекает время ожидания, либо MCE уменьшается до одного ядра.
В следующем примере система имеет 32 ядра, а ЦП системы находится под давлением.
ReservedComputeForFastQueries составляет 60 (60%).
- Зарезервировано 20 ядер (19,2 округлено до 20) для быстрых запросов.
- Остальные 12 ядер выделены для затухающих запросов.
DecayIntervalCPUTime составляет 60 000 (1 минуту времени ЦП).
Жизненный цикл запроса может быть следующим, если он не истекает или не завершается:
| Этап | Состояние | Выполнение и планирование | MCE |
|---|---|---|---|
| 0 | Быстрый | MCE составляет 20 процессорных ядер (зарезервировано для быстрых запросов). Запрос выполняется в порядке очереди (FIFO) относительно других быстрых запросов с использованием 20 зарезервированных ядер. Интервал распада времени работы ЦП в 1 минуту исчерпан. |
20 = MIN(32/2˄0, 20) |
| 1 | Гнилой | MCE настроен на 12 ядер (12 оставшихся ядер не зарезервировано для быстрых запросов). Задания выполняются в зависимости от доступности до MCE. Интервал распада в 1 минуту времени ЦП отработан. |
12 = MIN(32/2^1, 12) |
| 2 | Гнилой | MCE имеет значение 8 ядер (четверть 32 общих ядер). Задания выполняются вплоть до MCE на основе их доступности. Интервал в 1 минуту времени ЦП истрачен. |
8 = MIN(32/2˄2, 12) |
| 3 | Гнилой | MCE настроено на 4 ядра. Задания выполняются на основе доступности до MCE. Интервал распада на 1 минуту процессорного времени завершён. |
4 = MIN(32/2˄3, 12) |
| 4 | Гнилой | MCE установлено на 2 ядра. Задания выполняются на основе доступности до MCE. Интервал распада на 1 минуту процессорного времени завершён. |
2 = MIN(32/2˄4, 12) |
| 5 | Гнилой | MCE установлен на 1 ядро. Задания выполняются на основе доступности до MCE. Интервал распада не применяется, так как запрос достиг нижнего предела. Дальнейшее разложение останавливается, когда достигается минимум в 1 ядро. |
1 = MIN(32/2˄5, 12) |
Если система находится под давлением центрального процессора, каждому запросу не будет назначено больше ядер, чем его MCE. Если все ядра в настоящее время используются запросами в соответствующих MCE, другие запросы ожидают, пока ядра не станут доступными. По мере появления доступных ядер выбирается самый старый приоритетный запрос на основе прошедшего календарного времени. MCE является ограничением под давлением; оно не гарантирует количество ядер в любой момент времени.