Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op:![]() SQL Server 2025 (17.x)
SQL Server 2025 (17.x) ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL-database in Microsoft Fabric
SQL-database in Microsoft Fabric
Dit artikel bevat een overzicht van het gebruik van ai-opties (kunstmatige intelligentie), zoals OpenAI en vectoren, voor het bouwen van intelligente toepassingen met de SQL-Database Engine in SQL Server en Azure SQL Managed Instance.
Zie Intelligent-toepassingen en AI voor Azure SQL Database en SQL Database in Fabric.
Ga naar de SQL AI-voorbeelden opslagplaats voor samples en voorbeelden.
Overzicht
Met grote taalmodellen (LLM's) kunnen ontwikkelaars AI-toepassingen maken met een vertrouwde gebruikerservaring.
Het gebruik van LLM's in toepassingen biedt meer waarde en een verbeterde gebruikerservaring wanneer de modellen op het juiste moment toegang hebben tot de juiste gegevens vanuit de database van uw toepassing. Dit proces staat bekend als Rag (Retrieval Augmented Generation) en de SQL-Database Engine heeft veel functies die ondersteuning bieden voor dit nieuwe patroon, waardoor het een geweldige database is om intelligente toepassingen te bouwen.
De volgende koppelingen bevatten voorbeeldcode van verschillende opties voor het bouwen van intelligente toepassingen:
| AI-optie | Description |
|---|---|
| SQL MCP Server | Een stabiele en beheerde interface voor uw database, waarmee een set hulpprogramma's en configuraties wordt gedefinieerd. |
| Azure OpenAI | Genereer insluitingen voor RAG en integreer met elk model dat wordt ondersteund door Azure OpenAI. |
| Vectoren | Informatie over het opslaan van vectoren en het gebruik van vectorfuncties in de database. |
| Azure AI Zoeken | Gebruik uw database samen met Azure AI Zoeken om LLM op uw gegevens te trainen. |
| Intelligente toepassingen | Leer hoe u een end-to-end-oplossing maakt met behulp van een gemeenschappelijk patroon dat in elk scenario kan worden gerepliceerd. |
SQL MCP Server in AI-toepassingen
SQL MCP Server bevindt zich rechtstreeks in het gegevenspad voor AI-agents.
- Als modellen aanvragen genereren, biedt de server een stabiele en beheerde interface voor uw database.
- In plaats van onbewerkt schema weer te geven of te vertrouwen op gegenereerde SQL, wordt alle toegang gerouteerd via een gedefinieerde set hulpprogramma's die worden ondersteund door uw configuratie.
Deze aanpak houdt interacties voorspelbaar en zorgt ervoor dat elke bewerking overeenkomt met de machtigingen en structuur die u definieert. Zie aka.ms/sql/mcp voor meer informatie.
Door redenering van uitvoering te scheiden, richten modellen zich op intentie terwijl SQL MCP Server verwerkt hoe die intentie geldige query's wordt. Omdat het oppervlak beperkt en beschreven is, kunnen agents beschikbare mogelijkheden detecteren, in- en uitvoer begrijpen en werken zonder te raden. Dit ontwerp vermindert fouten en verwijdert de noodzaak voor complexe prompt-engineering om dubbelzinnigheid van schema's te compenseren.
Voor ontwikkelaars betekent deze aanpak dat AI veilig kan deelnemen aan echte workloads.
U kunt het volgende doen:
- Entiteiten eenmaal definiëren
- Rollen en beperkingen toepassen
Vervolgens het platform:
- Dwingt entiteiten, rollen en beperkingen consistent af
- Hiermee maakt u een betrouwbare basis voor op agents gestuurde toepassingen via SQL-gegevens.
Dezelfde configuratie die REST en GraphQL mogelijk maakt, is ook van toepassing op MCP, dus er is geen duplicatie van regels of logica. Zie aka.ms/dab/docs voor meer informatie.
Belangrijkste concepten voor het implementeren van RAG met Azure OpenAI
Deze sectie bevat belangrijke concepten die essentieel zijn voor het implementeren van RAG met Azure OpenAI in de SQL-Database Engine.
Ophaal-Versterkte Generatie (RAG)
RAG is een techniek die het vermogen van de LLM verbetert om relevante en informatieve antwoorden te produceren door extra gegevens uit externe bronnen op te halen. Rag kan bijvoorbeeld query's uitvoeren op artikelen of documenten die domeinspecifieke kennis bevatten met betrekking tot de vraag of prompt van de gebruiker. De LLM kan deze opgehaalde gegevens vervolgens gebruiken als verwijzing bij het genereren van het antwoord. Een eenvoudig RAG-patroon met behulp van de SQL-Database Engine kan bijvoorbeeld het volgende zijn:
- Gegevens invoegen in een tabel.
- Koppel uw exemplaar aan Azure AI Zoeken.
- Maak een Azure OpenAI GPT-4-model en verbind het met Azure AI Zoeken.
- Chat en stel vragen over uw gegevens met behulp van het getrainde Azure OpenAI-model vanuit uw toepassing en vanuit gegevens in uw exemplaar.
Het RAG-patroon, met prompt engineering, is bedoeld om de responskwaliteit te verbeteren door meer contextuele informatie aan het model te bieden. MET RAG kan het model een bredere knowledge base toepassen door relevante externe bronnen in het generatieproces op te nemen, wat resulteert in uitgebreidere en geïnformeerde antwoorden. Zie voor meer informatie over grounding LLMs Grounding LLMs - Microsoft Community Hub.
Prompts en promptopbouw
Een prompt is specifieke tekst of informatie die dient als instructie voor een groot taalmodel (LLM) of als contextuele gegevens waarop de LLM kan bouwen. Een prompt kan verschillende vormen aannemen, zoals een vraag, een instructie of zelfs een codefragment.
Voorbeeldprompts die u kunt gebruiken om een antwoord van een LLM te genereren, zijn onder andere:
- Instructies: instructies geven aan de LLM
- Primaire inhoud: geeft informatie aan de LLM voor verwerking
- Voorbeelden: het model aan een bepaalde taak of een bepaald proces aanpassen
- Aanwijzingen: de uitvoer van de LLM in de juiste richting sturen
- Ondersteunende inhoud: vertegenwoordigt aanvullende informatie die de LLM kan gebruiken om uitvoer te genereren
Het proces voor het maken van goede prompts voor een scenario wordt prompt engineering genoemd. Zie Prompt engineering-technieken voor meer informatie over prompts en best practices voor prompt engineering.
Tokens
Tokens zijn kleine stukken tekst die worden gegenereerd door de invoertekst op te splitsen in kleinere segmenten. Deze segmenten kunnen woorden of groepen tekens zijn, variërend van één teken tot een heel woord. Het woord hamburger is bijvoorbeeld onderverdeeld in tokens zoals ham, buren ger terwijl een kort en gemeenschappelijk woord als pear één token wordt beschouwd.
In Azure OpenAI wordt invoertekst door de API getokeniseerd. Het aantal tokens dat in elke API-aanvraag wordt verwerkt, is afhankelijk van factoren zoals de lengte van de invoer-, uitvoer- en aanvraagparameters. Het aantal tokens dat wordt verwerkt, heeft ook invloed op de reactietijd en doorvoer van de modellen. Elk model heeft limieten voor het aantal tokens dat het kan aannemen in één aanvraag en reactie van Azure OpenAI. Zie Azure OpenAI in Azure AI Foundry Modellenquota en -limieten voor meer informatie.
Vectors
Vectoren zijn geordende matrices van getallen (meestal floats) die informatie over sommige gegevens kunnen vertegenwoordigen. Een afbeelding kan bijvoorbeeld worden weergegeven als een vector van pixelwaarden, of een tekenreeks met tekst kan worden weergegeven als een vector van ASCII-waarden. Het proces om gegevens om te zetten in een vector wordt vectorisatie genoemd. Zie Vector-voorbeelden voor meer informatie.
Werken met vectorgegevens is eenvoudiger met de introductie van het vectorgegevenstype en vectorfuncties.
Embedderingen
Insluitingen zijn vectoren die belangrijke functies van gegevens vertegenwoordigen. Insluitingen worden vaak geleerd met behulp van een Deep Learning-model en machine learning- en AI-modellen gebruiken ze als functies. Insluitingen kunnen ook semantische overeenkomsten tussen vergelijkbare concepten vastleggen. Wanneer u bijvoorbeeld een insluiting voor de woorden person genereert en humanu kunt verwachten dat hun insluitingen (vectorweergave) vergelijkbaar zijn in waarde, omdat de woorden ook semantisch vergelijkbaar zijn.
Azure OpenAI biedt modellen voor het creëren van embeddings op basis van tekstgegevens. De service breekt tekst op in tokens en genereert insluitingen met behulp van modellen die vooraf zijn getraind door OpenAI. Voor meer informatie, zie Understand embeddings in Azure OpenAI in Azure AI Foundry Models.
Zoeken met vectoren
Vectorzoekopdrachten zijn het proces van het vinden van alle vectoren in een gegevensset die semantisch vergelijkbaar zijn met een specifieke queryvector. Daarom zoekt een queryvector voor het woord human in de hele woordenlijst naar semantisch vergelijkbare woorden en moet het woord person als een nauwe overeenkomst worden gevonden. Deze nabijheid, of afstand, wordt gemeten met behulp van een overeenkomstwaarde, zoals cosinus-gelijkenis. De dichtere vectoren zijn vergelijkbaar, hoe kleiner de afstand tussen deze vectoren.
Overweeg een scenario waarin u een query uitvoert op miljoenen documenten om de meest vergelijkbare documenten in uw gegevens te vinden. U kunt insluitingen maken voor uw gegevens en documenten opvragen met behulp van Azure OpenAI. Vervolgens kunt u een vectorzoekopdracht uitvoeren om de meest vergelijkbare documenten uit uw gegevensset te vinden. Het uitvoeren van een vectorzoekopdracht in een paar voorbeelden is echter triviaal. Het uitvoeren van dezelfde zoekopdracht op duizenden of miljoenen gegevenspunten wordt lastig. Er zijn ook afwegingen tussen uitgebreide zoekmethoden en benaderingsmethoden voor het vinden van dichtstbijzijnde buren (ANN-zoekmethoden), zoals latentie, doorvoersnelheid, nauwkeurigheid en kosten. Al deze afwegingen zijn afhankelijk van de vereisten van uw toepassing.
U kunt efficiënt vectoren opslaan en opvragen in de SQL-Database Engine, zoals beschreven in de volgende secties. Met deze mogelijkheid kunt u precies de dichtstbijzijnde buren zoeken met geweldige prestaties. U hoeft niet te beslissen tussen nauwkeurigheid en snelheid: u kunt beide hebben. Het opslaan van vector-insluitingen naast de gegevens in een geïntegreerde oplossing minimaliseert de noodzaak om gegevenssynchronisatie te beheren en versnelt uw time-to-market voor de ontwikkeling van AI-toepassingen.
Azure OpenAI
Insluiten is het proces van het weergeven van de echte wereld als gegevens. U kunt tekst, afbeeldingen of geluiden converteren naar insluitingen. Azure OpenAI-modellen kunnen echte informatie transformeren in insluitingen. U hebt toegang tot de modellen als REST-eindpunten, zodat u ze eenvoudig kunt gebruiken vanuit de SQL-Database Engine met behulp van de opgeslagen procedure sp_invoke_external_rest_endpoint. Deze procedure is beschikbaar vanaf SQL Server 2025 (17.x) en Azure SQL Managed Instance geconfigureerd met het Always-up-to-date update policy.
DECLARE @retval AS INT,
@response AS NVARCHAR (MAX),
@payload AS NVARCHAR (MAX);
SET @payload = JSON_OBJECT('input':@text);
EXECUTE
@retval = sp_invoke_external_rest_endpoint
@url = 'https://<openai-url>/openai/deployments/<model-name>/embeddings?api-version = 2023-03-15-preview',
@method = 'POST',
@credential = [https://<openai-url>/openai/deployments/<model-name>],
@payload = @payload,
@response = @response OUTPUT;
DECLARE @e AS VECTOR(1536) = JSON_QUERY(@response, '$.result.data[0].embedding');
Het gebruik van een aanroep naar een REST-service om insluitingen te krijgen, is slechts een van de integratieopties die u hebt bij het werken met SQL Managed Instance en OpenAI. U kunt alle beschikbare modellen toegang geven tot gegevens die zijn opgeslagen in de SQL-Database Engine om oplossingen te maken waar uw gebruikers kunnen communiceren met de gegevens, zoals het volgende voorbeeld:
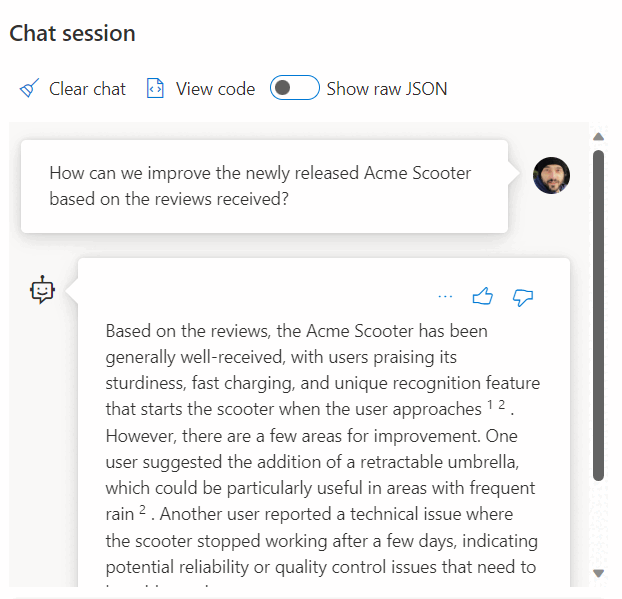
Zie de volgende artikelen, die ook van toepassing zijn op SQL Server en Azure SQL Managed Instance voor meer voorbeelden over het gebruik van Azure SQL en OpenAI:
- Afbeeldingen genereren met Azure OpenAI Service (DALL-E) en Azure SQL
- Using OpenAI REST Endpoints with Azure SQL
Vectorvoorbeelden
Het toegewijde vectorgegevenstype slaat vectorgegevens op efficiënte wijze op en bevat een reeks functies om ontwikkelaars te helpen bij het stroomlijnen van de implementatie van vectoren en gelijkeniszoekacties. U kunt de afstand tussen twee vectoren in één regel code berekenen met behulp van de nieuwe VECTOR_DISTANCE functie. Zie Vectorzoekopdrachten en vectorindexen in sql Database Engine voor meer informatie en voorbeelden.
Voorbeeld:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[embedding] [vector](1536) NOT NULL,
)
GO
SELECT TOP(10)
*
FROM
[dbo].[wikipedia_articles_embeddings_titles_vector]
ORDER BY
VECTOR_DISTANCE('cosine', @my_reference_vector, embedding)
Azure AI Zoeken
Implementeer RAG-patronen met behulp van de SQL-Database Engine en Azure AI Zoeken. U kunt ondersteunde chatmodellen uitvoeren op gegevens die zijn opgeslagen in de SQL-Database Engine zonder dat u modellen hoeft te trainen of af te stemmen door Azure AI Zoeken te integreren met Azure OpenAI en de SQL-Database Engine. Wanneer u modellen op uw gegevens uitvoert, kunt u met uw gegevens chatten en deze met grotere nauwkeurigheid en snelheid analyseren.
Zie de volgende artikelen voor meer informatie over de integratie van Azure AI Zoeken met Azure OpenAI en de SQL-Database Engine. Deze artikelen zijn ook van toepassing op SQL Server en Azure SQL Managed Instance:
- Azure OpenAI op uw gegevens
- Rag (Retrieval Augmented Generation) in Azure AI Zoeken
- Vector Zoeken met Azure SQL en Azure AI Zoeken
Intelligente toepassingen
U kunt de SQL-Database Engine gebruiken om intelligente toepassingen te bouwen die AI-functies bevatten, zoals aanbeveelders en Rag (Retrieval Augmented Generation), zoals in het volgende diagram wordt getoond:

Zie voor een end-to-end-voorbeeld waarin wordt getoond hoe u een AI-toepassing bouwt met behulp van sessies die abstract zijn als voorbeeldgegevensset:
- Hoe ik in 1 uur een sessie-aanbeveling heb gemaakt met behulp van OpenAI.
- Use Retrieval Augmented Generation om een vergadersessieassistent te bouwen.
Opmerking
LangChain-integratie en Semantic Kernel-integratie zijn afhankelijk van het gegevenstype vector deze is beschikbaar vanaf SQL Server 2025 (17.x) en in Azure SQL Managed Instance geconfigureerd met het updatebeleid Always-up-to-date of SQL Server 2025 updatebeleid, Azure SQL Database en SQL-database in Microsoft Fabric.
LangChain-integratie
LangChain is een bekend framework voor het ontwikkelen van toepassingen die mogelijk worden gemaakt door taalmodellen. Zie voor voorbeelden die laten zien hoe u LangChain kunt gebruiken om een chatbot op uw eigen gegevens te maken:
- langchain-sqlserver PyPI-pakket.
Enkele voorbeelden van het gebruik van Azure SQL met LangChain:
End-to-end voorbeelden:
- Bouw binnen 1 uur een chatbot op uw eigen data met Azure SQL, Langchain en Chainlit: Bouw een chatbot met behulp van het RAG-patroon op uw eigen data door LangChain te gebruiken voor het orkestreren van LLM-oproepen en Chainlit voor de gebruikersinterface.
Integratie van Semantic Kernel
Semantic Kernel is een opensource-SDK die u kunt gebruiken om eenvoudig agents te bouwen die uw bestaande code aanroepen. Als zeer uitbreidbare SDK kunt u Semantic Kernel gebruiken met modellen van OpenAI, Azure OpenAI, Hugging Face en meer. Door uw bestaande C#, Python en Java code te combineren met deze modellen, kunt u agents bouwen die vragen beantwoorden en processen automatiseren.
Een voorbeeld van hoe eenvoudig Semantic Kernel u helpt bij het bouwen van oplossingen met AI is:
- De ultieme chatbot?: Bouw een chatbot op uw eigen gegevens met zowel NL2SQL- als RAG-patronen voor de ultieme gebruikerservaring.