Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Los puntos de conexión de Batch permiten implementar modelos que ejecutan la inferencia en grandes volúmenes de datos. Estos puntos de conexión simplifican el hospedaje de modelos para la puntuación por lotes, por lo que puede centrarse en el aprendizaje automático en lugar de en la infraestructura.
Use puntos de conexión por lotes para implementar modelos cuando:
- Se usan modelos costosos que tardan más tiempo en ejecutarse la inferencia.
- La inferencia se realiza en grandes cantidades de datos distribuidos en varios archivos.
- No necesita una latencia baja.
- Aprovechas la paralelización.
En este artículo se muestra cómo usar un punto de conexión por lotes para implementar un modelo de aprendizaje automático que resuelve el problema de reconocimiento de dígitos clásico de MNIST (Modified National Institute of Standards and Technology). El modelo implementado realiza la inferencia por lotes en grandes cantidades de datos, como los archivos de imagen. El proceso comienza con la creación de una implementación por lotes de un modelo creado mediante Torch. Esta implementación se convierte en la predeterminada en el punto de conexión. Más adelante, cree una segunda implementación de un modelo compilado con TensorFlow (Keras), pruebe la segunda implementación y establézcala como implementación predeterminada del punto de conexión.
Requisitos previos
Antes de seguir los pasos descritos en este artículo, asegúrese de que tiene los siguientes requisitos previos:
Suscripción a Azure. Si no tiene una suscripción de Azure, cree una cuenta gratuita antes de empezar. Pruebe la versión gratuita o de pago de Azure Machine Learning.
Un área de trabajo de Azure Machine Learning. Si no tuvieras uno, sigue los pasos descritos en el artículo Cómo administrar áreas de trabajo para crear uno.
Para realizar las siguientes tareas, asegúrese de que tiene estos permisos en el área de trabajo:
Para crear o administrar puntos de conexión e implementaciones por lotes: Utilice el rol de propietario, el rol de colaborador o un rol personalizado que permita
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*.Para crear implementaciones de ARM en el grupo de recursos del área de trabajo: Utilice el rol propietario, el rol de colaborador o un rol personalizado, lo que permite
Microsoft.Resources/deployments/writeen el grupo de recursos donde se implementa el área de trabajo.
Es necesario instalar el siguiente software para trabajar con Azure Machine Learning:
SE APLICA A:
Extensión de ML de la CLI de Azure v2 (actual)La CLI de Azure y la
mlextensión para Azure Machine Learning.az extension add -n ml
Clone el repositorio de ejemplos
El ejemplo de este artículo se basa en ejemplos de código contenidos en el repositorio azureml-examples. Para ejecutar los comandos de forma local sin tener que copiar/pegar YAML y otros archivos, primero clona el repositorio y luego cambia los directorios a la carpeta:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
Preparación del sistema
Conexión con su área de trabajo
En primer lugar, conéctese al área de trabajo de Azure Machine Learning donde trabaja.
Si aún no ha establecido los valores predeterminados de la CLI de Azure, guarde la configuración predeterminada. Para evitar escribir los valores de la suscripción, el área de trabajo, el grupo de recursos y la ubicación varias veces, ejecute este código:
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Creación del proceso
Los puntos de conexión de Batch se ejecutan en clústeres de proceso y admiten clústeres de proceso de Azure Machine Learning (AmlCompute) y clústeres de Kubernetes. Los clústeres son un recurso compartido, por lo tanto, un clúster puede hospedar una o varias implementaciones por lotes (junto con otras cargas de trabajo, si lo desea).
Cree un proceso denominado batch-cluster, como se muestra en el código siguiente. Ajuste según sea necesario y haga referencia a su computación mediante azureml:<your-compute-name>.
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
Nota:
No se le cobra por el proceso en este momento, ya que el clúster permanece en 0 nodos hasta que se invoca un punto de conexión por lotes y se envía un trabajo de puntuación por lotes. Para obtener más información sobre los costos de proceso, consulte Administración y optimización del costo de AmlCompute.
Creación de un punto de conexión por lotes
Un punto de conexión por lotes es un punto de conexión HTTPS al que los clientes llaman para desencadenar un trabajo de puntuación por lotes. Un trabajo de procesamiento por lotes evalúa varias entradas. Una implementación por lotes es un conjunto de recursos de proceso que hospedan el modelo que realiza la puntuación por lotes (o la inferencia por lotes). Un punto de conexión por lotes puede tener varias implementaciones. Para más información sobre los puntos de conexión por lotes, consulte ¿Qué son los puntos de conexión por lotes?.
Sugerencia
Una de las implementaciones por lotes actúa como la implementación predeterminada para el punto de conexión. Cuando se invoca el punto de conexión, la implementación predeterminada realiza la puntuación por lotes. Para obtener más información sobre los puntos de conexión y las implementaciones por lotes, consulte Batch Endpoints and batch deployment (Puntos de conexión por lotes e implementación por lotes).
Nombre del punto de conexión. El nombre del punto de conexión debe ser único dentro de una región de Azure porque el nombre se incluye en el URI del punto de conexión. Por ejemplo, solo puede haber un punto de conexión por lotes con el nombre
mybatchendpointenwestus2.Coloque el nombre del punto de conexión en una variable para hacer referencia a él fácilmente más adelante.
ENDPOINT_NAME="mnist-batch"Configuración del punto de conexión por lotes
El siguiente archivo YAML define un punto de conexión por lotes. Use este archivo con el comando de la CLI para la creación de puntos de conexión por lotes.
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learningEn la tabla siguiente se describen las propiedades clave del punto de conexión. Para el esquema de YAML de punto de conexión por lotes completo, consulte Esquema de YAML de punto de conexión por lotes de la CLI (v2).
Clave Descripción nameEl nombre del punto de conexión por lotes. Es preciso que sea único en el nivel de región de Azure. descriptionDescripción del punto de conexión por lotes. Esta propiedad es opcional. tagsEtiquetas que se van a incluir en el punto de conexión. Esta propiedad es opcional. Cree el punto de conexión:
Ejecute este código para crear un punto de conexión por lotes.
az ml batch-endpoint create --file endpoint.yml --name $ENDPOINT_NAME
Creación de una implementación por lotes
Una implementación de modelo es un conjunto de recursos necesarios para hospedar el modelo que realiza la inferencia real. Para crear una implementación de modelos por lotes, necesita los siguientes elementos:
- Un modelo registrado en el área de trabajo
- El código para puntuar el modelo
- Un entorno con las dependencias del modelo instaladas
- Configuración de recursos y proceso creado previamente
Comience registrando el modelo para implementar, un modelo Torch para el popular problema de reconocimiento de dígitos (MNIST). Las implementaciones de Batch solo pueden implementar modelos registrados en el área de trabajo. Puede omitir este paso si el modelo que desea implementar ya está registrado.
Sugerencia
Los modelos están asociados a la implementación en lugar de estar asociados al punto de conexión. Esto significa que un único punto de conexión puede servir diferentes modelos (o versiones de modelo) en el mismo punto de conexión siempre que los diferentes modelos (o versiones del modelo) se implementen en distintas implementaciones.
MODEL_NAME='mnist-classifier-torch' az ml model create --name $MODEL_NAME --type "custom_model" --path "deployment-torch/model"Ahora es el momento de crear un script de puntuación. Las implementaciones por lotes requieren un script de puntuación que indique cómo se debe ejecutar el modelo especificado y cómo se deben procesar los datos de entrada. Los puntos de conexión de Batch admiten scripts creados en Python. En este caso, se implementa un modelo que lee los archivos de imagen que representan dígitos y genera el dígito correspondiente. El script de puntuación tiene el siguiente aspecto:
Nota:
En el caso de los modelos de MLflow, Azure Machine Learning genera automáticamente el script de puntuación, por lo que no es necesario proporcionar uno. Si el modelo es un modelo de MLflow, puede omitir este paso. Para obtener más información sobre cómo funcionan los puntos de conexión por lotes con modelos de MLflow, consulte el artículo Uso de modelos de MLflow en implementaciones por lotes.
Advertencia
Si va a implementar un modelo de aprendizaje automático automatizado (AutoML) en un punto de conexión por lotes, tenga en cuenta que el script de puntuación que AutoML proporciona solo funciona para los puntos de conexión en línea y no está diseñado para la ejecución por lotes. Para obtener información sobre cómo crear un script de puntuación para la implementación por lotes, consulte Creación de scripts de puntuación para implementaciones por lotes.
deployment-torch/code/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)Cree un entorno en el que se ejecute la implementación por lotes. El entorno debe incluir los paquetes
azureml-coreyazureml-dataset-runtime[fuse], que son necesarios para los puntos de conexión por lotes, además de cualquier dependencia que requiera el código para ejecutarse. En este caso, las dependencias se han capturado en un archivoconda.yaml:deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]Importante
Las implementaciones por lotes requieren los paquetes
azureml-coreyazureml-dataset-runtime[fuse], y deben incluirse en las dependencias del entorno.Especifique el entorno de la siguiente manera:
La definición de entorno se incluye en la propia definición de implementación como un entorno anónimo. Verá en las líneas siguientes en la implementación:
environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest conda_file: environment/conda.yamlVaya a la pestaña Entornos en el menú lateral.
Seleccione entornos personalizados>Crear.
Escriba el nombre del entorno, en este caso,
torch-batch-env.Para Seleccionar origen de entorno, seleccione Utilizar la imagen Docker existente con el archivo conda opcional.
En Ruta a la imagen del registro de contenedor, escriba
mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04.Seleccione Siguiente para ir a la sección "Personalizar".
Copie el contenido del archivo deployment-torch/environment/conda.yaml desde el repositorio de GitHub en el portal.
Seleccione Siguiente hasta llegar a la "Página de revisión".
Seleccione Crear y espere a que el entorno esté listo.
Advertencia
Los entornos mantenidos no se admiten en las implementaciones por lotes. Debe especificar su propio entorno. Siempre puede usar la imagen base de un entorno mantenido como su entorno para simplificar el proceso.
Creación de una definición de implementación
deployment-torch/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: infoEn la tabla siguiente se describen las propiedades clave de la implementación por lotes. Para el esquema de YAML de implementación por lotes completo, consulte Esquema de YAML de implementación por lotes de la CLI (v2).
Clave Descripción nameNombre de la implementación. endpoint_nameEl nombre del punto de conexión en el que se creará la implementación. modelModelo que se va a usar para la puntuación por lotes. En el ejemplo se define un modelo en línea mediante path. Esta definición permite que los archivos de modelo se carguen y registren automáticamente con un nombre y una versión generados automáticamente. Consulte el esquema del modelo para obtener más opciones. Como procedimiento recomendado para escenarios de producción, debe crear el modelo por separado y hacerle referencia aquí. Para hacer referencia a un modelo existente, use la sintaxisazureml:<model-name>:<model-version>.code_configuration.codeEl directorio local que contiene todo el código fuente Python para puntuar el modelo. code_configuration.scoring_scriptArchivo de Python en el directorio code_configuration.code. Este archivo debe tener una funcióninit()y una funciónrun(). Utilice la funcióninit()para cualquier preparación costosa o común (por ejemplo, para cargar el modelo en memoria).init()se llama solo una vez al principio del proceso. Userun(mini_batch)para puntuar cada entrada; el valor demini_batches una lista de rutas de acceso de archivo. La funciónrun()debe devolver un dataframe de Pandas o una matriz. Cada elemento devuelto indica una ejecución correcta del elemento de entrada enmini_batch. Para obtener más información sobre cómo crear un script de puntuación, consulte Descripción del script de puntuación.environmentEl entorno en el que se va a puntuar el modelo. En el ejemplo se define un entorno en línea mediante conda_fileyimage. Las dependencias deconda_filese instalan encima deimage. El entorno se registra automáticamente con un nombre y una versión generados automáticamente. Consulte el esquema de entorno para obtener más opciones. Como procedimiento recomendado para escenarios de producción, debe crear el entorno por separado y hacerle referencia aquí. Para hacer referencia a un entorno existente, use la sintaxisazureml:<environment-name>:<environment-version>.computeEl proceso para ejecutar la puntuación por lotes. En el ejemplo se usa el batch-clustercreado al principio y se hace referencia a él mediante la sintaxisazureml:<compute-name>.resources.instance_countEl número de instancias que se usarán para cada trabajo de puntuación por lotes. settings.max_concurrency_per_instanceNúmero máximo de ejecuciones de scoring_scriptparalelas por instancia.settings.mini_batch_sizeNúmero de archivos que scoring_scriptpuede procesar en una llamada arun().settings.output_actionCómo se debe organizar la salida en el archivo de salida. append_rowcombina todos los resultados de salida devueltos derun()en un único archivo denominadooutput_file_name.summary_onlyno combinará los resultados de salida y solo calcularáerror_threshold.settings.output_file_nameEl nombre del archivo de salida de puntuación por lotes para append_rowoutput_action.settings.retry_settings.max_retriesEl número máximo de intentos erróneos de scoring_scriptrun().settings.retry_settings.timeoutEl tiempo de espera en segundos para scoring_scriptrun()para puntuar un mini lote.settings.error_thresholdEl número de errores de puntuación de archivo de entrada que se deben omitir. Si el recuento de errores de toda la entrada supera este valor, el trabajo de puntuación por lotes se termina. En el ejemplo se usa -1, que indica que se permite cualquier número de errores sin que se termine el trabajo de puntuación por lotes.settings.logging_levelnivel de detalle del registro. Los valores en el aumento del nivel de detalle son: WARNING, INFO y DEBUG. settings.environment_variablesDiccionario de pares nombre-valor de variable de entorno que se establecerán para cada trabajo de puntuación por lotes. Vaya a la pestaña Puntos de conexión en el menú lateral.
Seleccione la pestaña Puntos de conexión por lotes>Crear.
Asigne un nombre al punto de conexión, en este caso,
mnist-batch. Puede configurar el resto de los campos o dejarlos en blanco.Seleccione Siguiente para ir a la sección "Modelo".
Seleccione el modelo mnist-classifier-torch.
Seleccione Siguiente para ir a la página "Implementación".
Asigne un nombre a la implementación.
En Acción de salida, asegúrese de que la opción Anexar fila está seleccionada.
En nombre de archivo de salida, asegúrese de que el archivo de salida de puntuación por lotes es el que necesita. El valor predeterminado es
predictions.csv.En tamaño de lote mini, ajuste el tamaño de los archivos que se incluirán en cada minilote. Este tamaño controla la cantidad de datos que recibe el script de puntuación por lote.
En tiempo de espera de puntuación (segundos), asegúrese de que proporciona tiempo suficiente para que la implementación pueda puntuar un lote determinado de archivos. Si aumenta el número de archivos, normalmente también tiene que aumentar el valor de tiempo de espera. Los modelos más caros (como los basados en el aprendizaje profundo) pueden requerir valores altos en este campo.
En simultaneidad máxima por instancia, configure el número de ejecutores que desea tener para cada instancia de proceso que obtenga en la implementación. Un número mayor aquí garantiza un mayor grado de paralelización, pero también aumenta la presión de memoria en la instancia de proceso. Ajuste este valor junto con Tamaño del minilote.
Una vez hecho esto, seleccione Siguiente para ir a la página "Código y entorno".
En "Seleccionar un script de puntuación para la inferencia", busque y seleccione el archivo de script de puntuación deployment-torch/code/batch_driver.py.
En la sección "Seleccionar entorno", seleccione el entorno que creó anteriormente torch-batch-env.
Seleccione Siguiente para ir a la página "Proceso".
Seleccione el clúster de proceso que creó en un paso anterior.
Advertencia
Los clústeres de Azure Kubernetes se admiten en implementaciones por lotes, pero solo cuando se crean mediante la CLI de Azure Machine Learning o el SDK de Python.
En recuento de instancias, escriba el número de instancias de proceso que desea para la implementación. En este caso, utilice 2.
Seleccione Next (Siguiente).
Cree la implementación:
Ejecute el código siguiente para crear una implementación por lotes en el punto de conexión por lotes y establézcala como la implementación predeterminada.
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-defaultSugerencia
El parámetro
--set-defaultestablece la implementación recién creada como la implementación predeterminada del punto de conexión. Es una manera cómoda de crear una nueva implementación predeterminada del punto de conexión, especialmente para la primera creación de la implementación. Como procedimiento recomendado para escenarios de producción, es posible que desee crear una nueva implementación sin establecerla como predeterminada. Compruebe que la implementación funciona según lo previsto y, a continuación, actualice la implementación predeterminada más adelante. Para obtener más información sobre cómo implementar este proceso, consulte la sección Implementación de un nuevo modelo.Compruebe los detalles de la implementación y el punto de conexión por lotes.
Use
showpara comprobar los detalles del punto de conexión y la implementación. Para comprobar una implementación por lotes, ejecute el código siguiente:DEPLOYMENT_NAME="mnist-torch-dpl" az ml batch-deployment show --name $DEPLOYMENT_NAME --endpoint-name $ENDPOINT_NAMESeleccione la pestaña Puntos de conexión por lotes.
Seleccione el punto de conexión por lotes que desea ver.
La página Detalles del punto de conexión muestra los detalles del punto de conexión junto con todas las implementaciones disponibles en el punto de conexión.


Ejecución de puntos de conexión por lotes y resultados de acceso
Descripción del flujo de datos
Antes de ejecutar el punto de conexión por lotes, comprenda cómo fluyen los datos a través del sistema:
Entradas: datos que se van a procesar (puntuación). Esto incluye:
- Archivos almacenados en Azure Storage (Blob Storage, lago de datos)
- Carpetas con varios archivos
- Conjuntos de datos registrados en Azure Machine Learning
Procesamiento: el modelo implementado procesa los datos de entrada en lotes (miniprocesos) y genera predicciones.
Salidas: resultados del modelo, almacenados como archivos en Azure Storage. De forma predeterminada, las salidas se guardan en el almacenamiento de blobs predeterminado del área de trabajo, pero puede especificar una ubicación diferente.
Invocación de un punto de conexión por lotes
La invocación de un punto de conexión por lotes desencadena un trabajo de puntuación por lotes. El trabajo name se devuelve en la respuesta de invocación y realiza un seguimiento del progreso de la puntuación por lotes. Especifique la ruta de acceso de datos de entrada para que los puntos de conexión puedan localizar los datos que se van a evaluar. En el ejemplo siguiente se muestra cómo iniciar un nuevo trabajo sobre una muestra de datos del conjunto de datos MNIST almacenado en una cuenta de Azure Storage.
Puede ejecutar e invocar un punto de conexión por lotes mediante la CLI de Azure, el SDK de Azure Machine Learning o los puntos de conexión de REST. Para obtener más información sobre estas opciones, consulte Creación de trabajos y datos de entrada para puntos de conexión por lotes.
Nota:
¿Cómo funciona la paralelización?
Las implementaciones por lotes distribuyen el trabajo en el nivel de archivo. Por ejemplo, una carpeta con 100 archivos y mini lotes de 10 archivos genera 10 lotes de 10 archivos cada uno. Esto sucede independientemente del tamaño del archivo. Si los archivos son demasiado grandes para su procesamiento en miniprocesos, dividalos en archivos más pequeños para aumentar el paralelismo o reducir el número de archivos por minilote. Actualmente, las implementaciones de Batch no tienen en cuenta los sesgos en la distribución de tamaño de archivo.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $SAMPLE_INPUT_URI --input-type uri_folder --query name -o tsv)



Los puntos de conexión por lotes admiten la lectura de archivos o carpetas que se encuentran en diferentes ubicaciones. Para obtener más información sobre los tipos admitidos y cómo especificarlos, consulte Acceso a datos desde trabajos de puntos de conexión por lotes.
Supervisión del progreso de la ejecución del trabajo por lotes
Los trabajos de puntuación por lotes tardan tiempo en procesar todas las entradas.
El código siguiente comprueba el estado del trabajo y genera un vínculo a Estudio de Azure Machine Learning para obtener más detalles.
az ml job show -n $JOB_NAME --web

Comprobación de los resultados de la puntuación por lotes
Las salidas del trabajo se almacenan en el almacenamiento en la nube, ya sea en el almacenamiento de blobs predeterminado del área de trabajo o en el almacenamiento especificado. Para obtener información sobre cómo cambiar los valores predeterminados, consulte Configuración de la ubicación de salida. Los pasos siguientes le permiten ver los resultados de puntuación en el Explorador de Azure Storage cuando se completa el trabajo:
Ejecute el código siguiente para abrir el trabajo de puntuación por lotes en Estudio de Azure Machine Learning. El vínculo del estudio de trabajo se incluye también en la respuesta de
invoke, como el valor deinteractionEndpoints.Studio.endpoint.az ml job show -n $JOB_NAME --webEn el grafo del trabajo, seleccione el paso
batchscoring.Seleccione la pestaña Resultados y registros y, después, Show data outputs (Mostrar salidas de datos).
En Data outputs (Salidas de datos), seleccione el icono para abrir el Explorador de Storage.
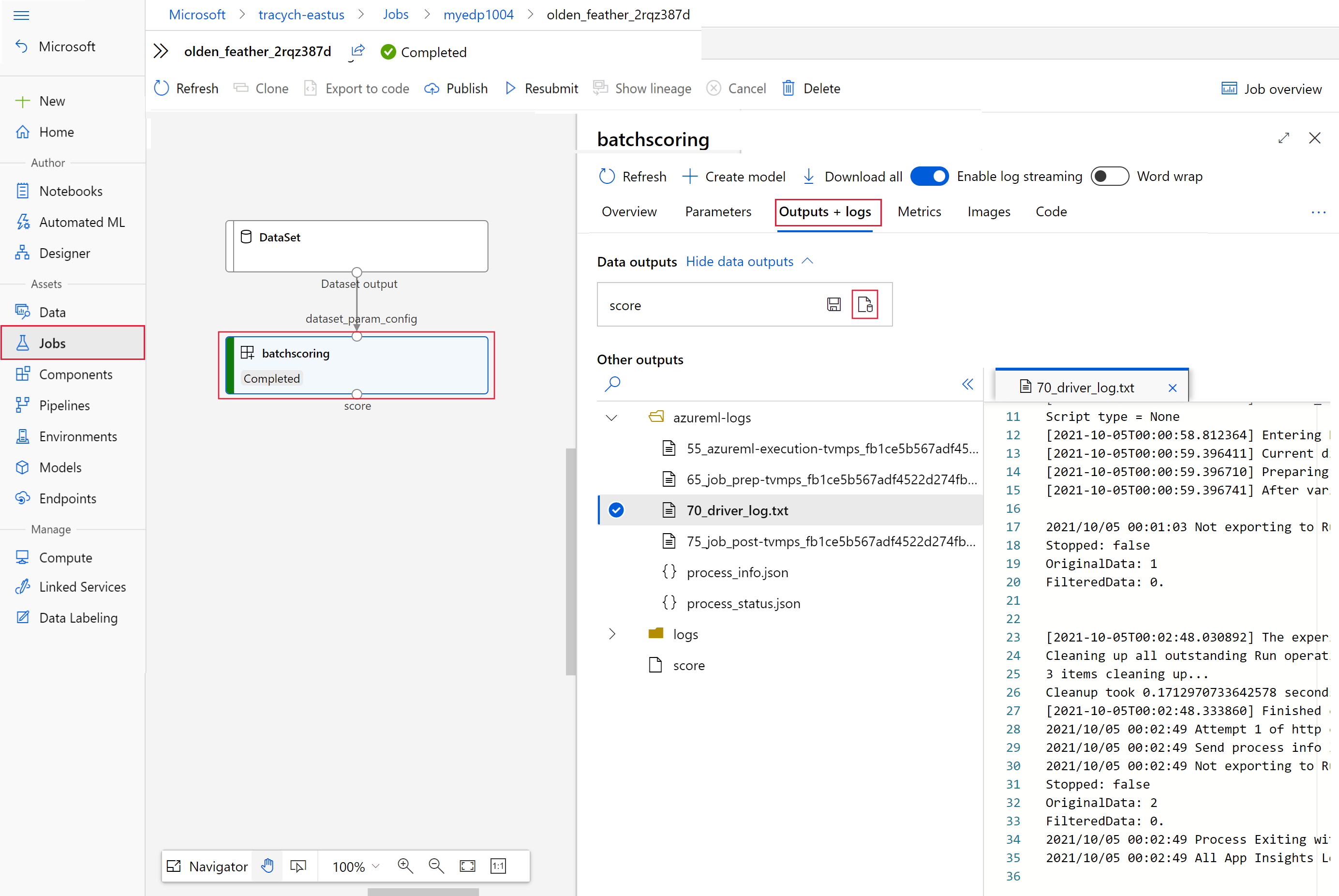
Los resultados de puntuación del Explorador de Storage son similares a la página de ejemplo siguiente:



Configuración de la ubicación de salida
De forma predeterminada, los resultados del puntaje por lotes se almacenan en el almacén de blobs predeterminado del área de trabajo en una carpeta nombrada según el trabajo (un GUID generado por el sistema). Configura la ubicación de salida al invocar el endpoint para procesamiento por lotes.
Use output-path para configurar cualquier carpeta en un almacén de datos registrado de Azure Machine Learning. La sintaxis de --output-path es la misma que --input cuando se especifica una carpeta, es decir, azureml://datastores/<datastore-name>/paths/<path-on-datastore>/. Use --set output_file_name=<your-file-name> para configurar un nuevo nombre de archivo de salida.
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $SAMPLE_INPUT_URI --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)

Advertencia
Debe usar una ubicación de salida única. Si el archivo de salida existe, se produce un error en el trabajo de puntuación por lotes.
Importante
A diferencia de las entradas, las salidas solo se pueden almacenar en almacenes de datos de Azure Machine Learning que se ejecutan en cuentas de almacenamiento de blobs.
Sobrescribir la configuración de implementación para cada trabajo
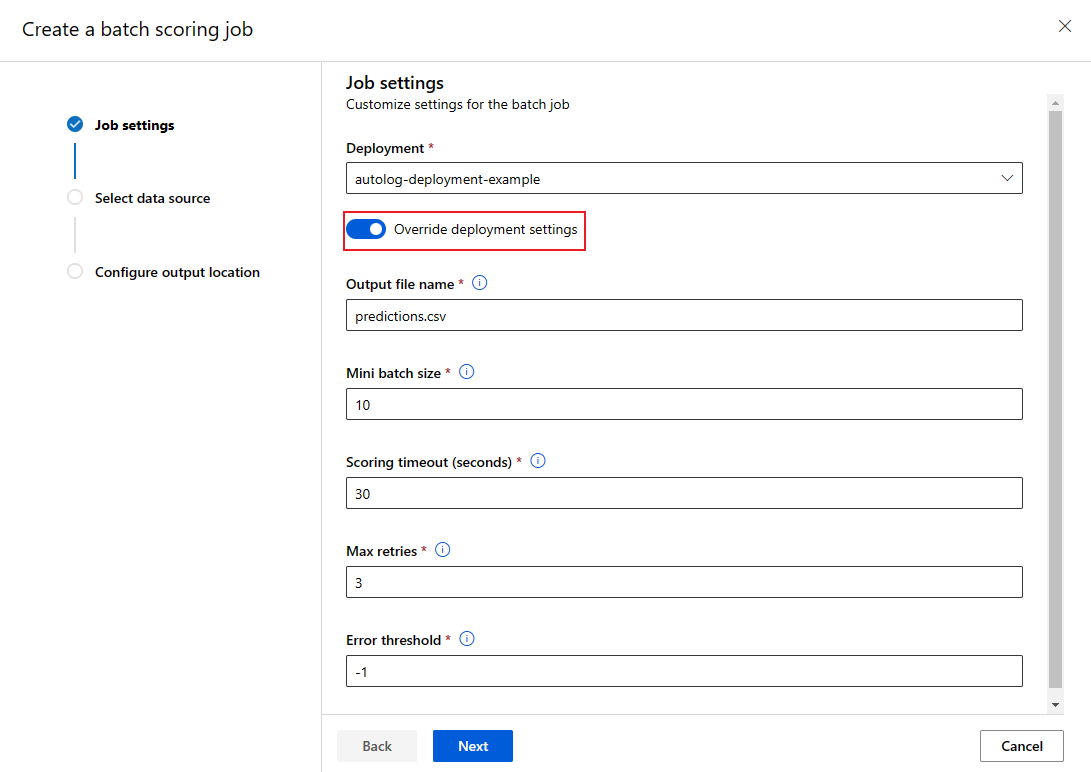
Al invocar un punto de conexión por lotes, puede sobrescribir algunas opciones de configuración para hacer el mejor uso de los recursos de proceso y mejorar el rendimiento. Esta característica es útil cuando se necesitan configuraciones diferentes para distintos trabajos sin modificar permanentemente la implementación.
¿Qué configuración se puede invalidar?
Puede configurar las siguientes opciones por trabajo:
| Configuración | Cuándo usar | Escenario de ejemplo |
|---|---|---|
| Recuento de instancias | Cuando tiene volúmenes de datos variables | Use más instancias para conjuntos de datos más grandes (10 instancias para 1 millón de archivos frente a 2 instancias para 100 000 archivos). |
| Tamaño de minilote | Cuando necesite equilibrar el rendimiento y el uso de memoria | Use lotes más pequeños (archivos de 10 a 50) para imágenes grandes y lotes más grandes (archivos de 100 a 500) para archivos de texto pequeños. |
| Número máximo de reintentos | Cuándo varía la calidad de los datos | Reintentos más altos (5-10) para datos ruidosos; reintentos inferiores (1-3) para datos limpios |
| Tiempo de espera | Cuando el tiempo de procesamiento varía según el tipo de datos | Tiempo de espera más largo (300s) para modelos complejos; tiempo de espera más corto (30s) para modelos simples |
| Umbral de error | Cuando necesite diferentes niveles de tolerancia a errores | Umbral estricto (-1) para trabajos críticos; umbral flexible (10%) para trabajos experimentales |
Cómo invalidar la configuración
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
Adición de implementaciones a un punto de conexión
Una vez que tenga un punto de conexión por lotes con una implementación, puede seguir refinando el modelo y agregar nuevas implementaciones. Los puntos de conexión por lotes seguirán sirviendo a la implementación predeterminada mientras desarrolla e implementa nuevos modelos en el mismo punto de conexión. Las implementaciones no afectan entre sí.
En este ejemplo, agregará una segunda implementación que usa un modelo compilado con Keras y TensorFlow para resolver el mismo problema de MNIST.
Adición de una segunda implementación
Cree un entorno para la implementación por lotes. Incluya las dependencias que el código necesita para ejecutarse. Agregue la biblioteca
azureml-core, ya que es necesario para las implementaciones por lotes. La siguiente definición de entorno incluye las bibliotecas necesarias para ejecutar un modelo con TensorFlow.La definición de entorno se incluye en la propia definición de implementación como un entorno anónimo.
environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest conda_file: environment/conda.yamlCopie el contenido del archivo deployment-keras/environment/conda.yaml desde el repositorio de GitHub en el portal.
Seleccione Siguiente hasta llegar a la "página Revisar".
Seleccione Crear y espere hasta que el entorno esté listo para su uso.
El archivo conda utilizado tiene el aspecto siguiente:
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]Cree un script de puntuación para el modelo:
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)Creación de una definición de implementación
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csvSeleccione Siguiente para continuar con la página "Código y entorno".
Para Seleccionar un script de puntuación para la inferencia, busque seleccionar el archivo de script de puntuación deployment-keras/code/batch_driver.py.
En Seleccionar entorno, seleccione el entorno que creó en un paso anterior.
Seleccione Next (Siguiente).
En la página Proceso, seleccione el clúster de proceso que creó en un paso anterior.
En recuento de instancias, escriba el número de instancias de proceso que desea para la implementación. En este caso, utilice 2.
Seleccione Next (Siguiente).
Cree la implementación:
Ejecute el código siguiente para crear una implementación por lotes en el punto de conexión por lotes y establézcala como la implementación predeterminada.
az ml batch-deployment create --file deployment-keras/deployment.yml --endpoint-name $ENDPOINT_NAMESugerencia
En este caso, falta el parámetro
--set-default. Como procedimiento recomendado para escenarios de producción, cree una nueva implementación sin establecerla como predeterminada. El siguiente paso es comprobarla y actualizar la implementación predeterminada más adelante.

Prueba de una implementación por lotes no predeterminada
Para probar la nueva implementación no predeterminada, debe conocer el nombre de la implementación que desea ejecutar.
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input $SAMPLE_INPUT_URI --input-type uri_folder --query name -o tsv)
Observe que --deployment-name se usa para especificar la implementación que se va a ejecutar. Este parámetro permite invoke una implementación no predeterminada sin actualizar la implementación predeterminada del punto de conexión por lotes.
Actualización de la implementación por lotes predeterminada
Aunque puede invocar una implementación específica dentro de un punto de conexión, normalmente querrá invocar el propio punto de conexión y dejar que el punto de conexión decida qué implementación usar, la implementación predeterminada. Puede cambiar la implementación predeterminada (y, en consecuencia, cambiar el modelo que atiende la implementación) sin cambiar el contrato con el usuario invocando el punto de conexión. Use el código siguiente para actualizar la implementación predeterminada:
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME

Eliminación del punto de conexión y la implementación por lotes
Si no necesita la implementación de lotes anterior, elimínela mediante la ejecución del código siguiente. La --yes marca confirma la eliminación.
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
Ejecute el código siguiente para eliminar el punto de conexión por lotes y sus implementaciones subyacentes. Los trabajos de puntuación por lotes no se eliminan.
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes