Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tip
Power BI Dataflow Gen1 befindet sich jetzt in einem Legacyzustand und erhält keine neuen Featureinvestitionen. Für Premium-Kunden mit Fabric-Zugriff ist Dataflow Gen2 der empfohlene Weg, der Verbesserungen an Leistung, Skalierung, Zuverlässigkeit, Funktionalität und integrierter KI bietet. Pro/PPU-Kunden können Gen1 weiterhin verwenden, während die Richtlinien für Gen2 sich für diese Szenarien weiterentwickeln. Anleitungen zum Upgrade von Dataflow Gen1 auf Dataflow Gen2 finden Sie unter dem Titel "Upgrade von Dataflow Gen1 auf Dataflow Gen2".
Sie können Dataflowworkloads in Ihrem Power BI Premium-Abonnement erstellen. Power BI verwendet das Konzept von Workloads, um Premium-Inhalte zu beschreiben. Zu Workloads zählen Datasets, paginierte Berichte, Dataflows und KI. Mit der Workload Dataflows können Sie die Self-Service-Datenaufbereitung von Dataflows nutzen, um Daten zu erfassen, zu transformieren, zu integrieren und zu erweitern. Power BI Premium-Dataflows werden über das Verwaltungsportal verwaltet.
In den folgenden Abschnitten wird beschrieben, wie Sie Dataflows in Ihrer Organisation aktivieren und wie Sie die Einstellungen in Ihrer Premium-Kapazität anpassen, und Sie erhalten eine Anleitung zur allgemeinen Verwendung.
Aktivieren von Dataflows in Power BI Premium
Die erste Voraussetzung für das Verwenden von Dataflows in Ihrem Premium-Abonnement in Power BI ist es, die Erstellung und Verwendung von Dataflows in Ihrer Organisation zu aktivieren. Klicken Sie im Verwaltungsportal auf Mandanteneinstellungen, und schalten Sie den Schieberegler unter Datafloweinstellungen auf Aktiviert, wie auf dem folgenden Bild zu sehen.
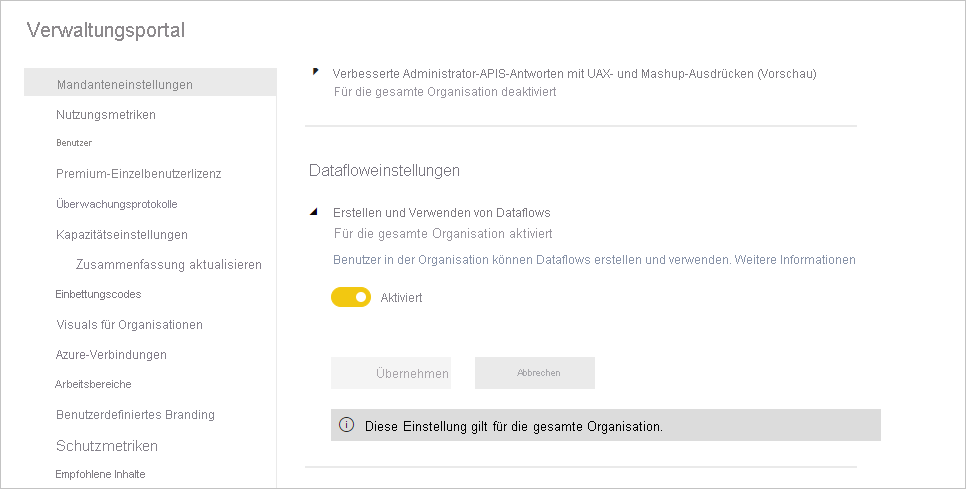
Nachdem Sie die Arbeitslast für Datenflüsse aktiviert haben, wird sie mit den Standardeinstellungen vorkonfiguriert. Sie können diese Einstellungen bei Bedarf entsprechend Ihren Anforderungen anpassen. Als Nächstes beschreiben wir, wo diese Einstellungen live sind, beschreiben sie die einzelnen Einstellungen, und helfen Ihnen zu verstehen, wann Sie die Werte ändern möchten, um ihre Datenflussleistung zu optimieren.
Optimieren der Datafloweinstellungen in Premium
Sobald Dataflows aktiviert sind, können Sie im Verwaltungsportal ändern oder anpassen, wie Dataflows erstellt werden und wie sie Ressourcen in Ihrer Power BI Premium-Kapazität verwenden. Power BI Premium erfordert keine Änderung der Arbeitsspeichereinstellungen. Der Speicher in Power BI Premium wird automatisch vom zugrunde liegenden System verwaltet. Die folgenden Schritte zeigen, wie Sie Ihre Datafloweinstellungen anpassen können.
Wählen Sie im Verwaltungsportal die Mandanteneinstellungen aus, um alle erstellten Kapazitäten auflisten zu können. Wählen Sie eine Kapazität aus, um ihre Einstellungen zu verwalten.
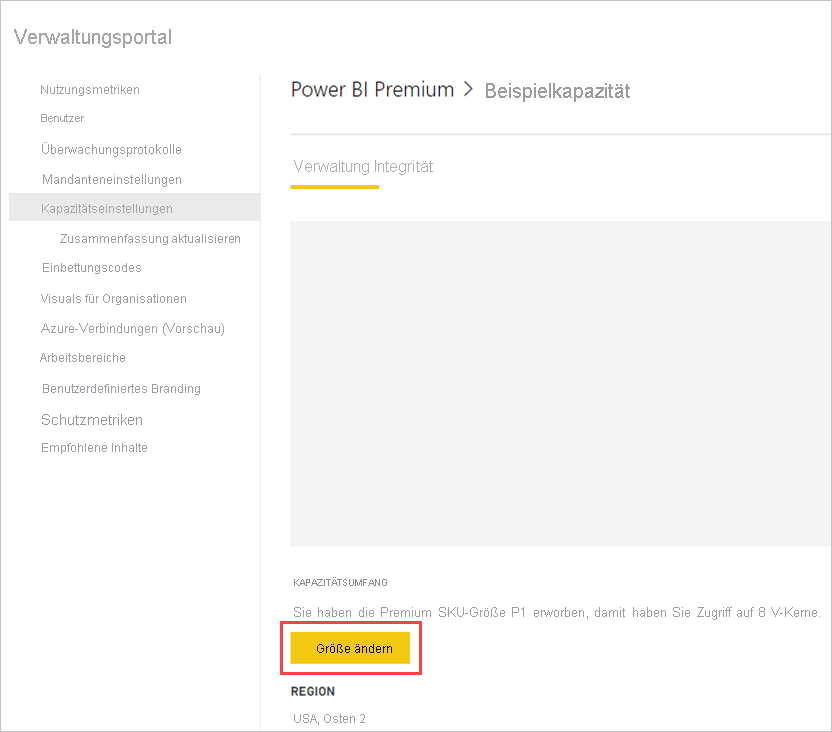
Ihre Power BI Premium-Kapazität spiegelt die Ressourcen wider, die für Ihre Dataflows verfügbar sind. Sie können den Umfang Ihrer Kapazität ändern, indem Sie wie auf folgender Abbildung gezeigt auf die Schaltfläche Größe ändern klicken.
SKUs mit Premium-Kapazität: Hochskalieren der Hardware
Power BI Premium-Workloads nutzen V-Kerne, um schnelle Abfragen für die verschiedenen Workloadtypen bereitzustellen. Kapazitäten und SKUs beinhaltet ein Diagramm, das die aktuellen Spezifikationen für jedes der verfügbaren Workloadangebote veranschaulicht. Kapazitäten von A3 und höher können den Vorteil der Compute Engine nutzen. Wenn Sie also die erweiterte Compute Engine nutzen möchten, beginnen Sie dort.
Optimierte Compute-Engine: Eine Möglichkeit zur Leistungssteigerung
Die optimierte Compute-Engine ist eine Engine, die Ihre Abfragen beschleunigen kann. Power BI verwendet eine Compute-Engine, um Ihre Abfragen und Aktualisierungsvorgänge zu verarbeiten. Das erweiterte Computemodul ist eine Verbesserung gegenüber dem Standardmodul und funktioniert durch Laden von Daten in einen SQL-Cache und verwendet SQL, um die Tabellentransformation, Aktualisierungsvorgänge zu beschleunigen und directQuery-Konnektivität zu ermöglichen. Wenn On oder Optimized für berechnete Entitäten konfiguriert ist, verwendet Power BI SQL, um die Leistung zu beschleunigen. Wenn für die Engine An festgelegt ist, ermöglicht dies auch die DirectQuery-Konnektivität. Stellen Sie sicher, dass die Nutzung des Datenflusses die erweiterte Compute-Engine ordnungsgemäß verwendet. Benutzer können die erweiterte Compute-Engine so konfigurieren, dass Sie pro Datenfluss eingeschaltet, optimiert oder ausgeschaltet wird.
Hinweis
Die optimierte Compute-Engine steht noch nicht in allen Regionen zur Verfügung.
Anleitung für häufige Szenarios
In diesem Abschnitt erhalten Sie eine Anleitung für häufige Szenarios, wenn Dataflowworkloads mit Power BI Premium verwendet werden.
Langsame Aktualisierungszeiten
Langsame Aktualisierungszeiten sind in der Regel der Parallelität geschuldet. Sie sollten sich die folgenden Optionen der Reihe nach ansehen:
Ein Hauptkonzept für langsame Aktualisierungszeiten liegt in der Natur der Datenaufbereitung. Wo immer möglich, sollten Sie langsame Aktualisierungszeiten optimieren, indem Sie vom Vorteil profitieren, dass die Datenquelle die Datenaufbereitung übernehmen und im Vorfeld Abfragelogik durchführen kann. Im konkreten Fall heißt dass, wenn Sie eine relationale Datenbank wie SQL als Quelle nutzen, sollten Sie überprüfen, ob die ursprüngliche Abfrage für die Quelle ausgeführt werden kann. Verwenden Sie diese Quellabfrage dann für Ihren ursprünglichen Extraktionsdataflow für die Datenquelle. Wenn Sie keine systemeigene Abfrage im Quellsystem verwenden können, führen Sie Vorgänge aus, die das Datenflussmodul in die Datenquelle falten kann.
Testen Sie, die Aktualisierungszeiten auf derselben Kapazität zu verteilen. Aktualisierungsvorgänge können als Prozess beschrieben werden, für den erhebliche Computeleistung erforderlich ist. In den Worten der Restaurantanalogie ist ein Verteilen der Aktualisierungszeiten gleichbedeutend mit einem Einschränken der Anzahl an Gästen in Ihrem Restaurant. Ebenso wie Restaurants Gäste einplanen und die Kapazität berücksichtigen, sollten Sie auch Aktualisierungsvorgänge in Zeiten durchführen, in denen die Nutzung nicht voll ausgelastet ist. Dies kann viele Vorteile dafür bieten, die Last auf der Kapazität abzumildern.
Wenn die Schritte in diesem Abschnitt nicht den gewünschten Parallelitätsgrad liefern können, sollten Sie Ihre Kapazität auf eine höhere SKU upgraden. Führen Sie dann noch einmal die vorherigen Schritte durch.
Verwenden der Compute-Engine zum Verbessern der Leistung
Führen Sie die folgenden Schritte aus, um zu ermöglichen, dass Workloads die Compute-Engine auslösen, und um stetig die Leistung zu verbessern:
Gehen Sie für berechnete und verknüpfte Entitäten im selben Workspace wie folgt vor:
Legen Sie den Fokus für die Datenerfassung darauf, die Daten schnellstmöglich in den Speicher zu laden. Verwenden Sie dazu nur Filter, wenn sie die Gesamtgröße des Dataset reduzieren. Als Best Practice gilt, Ihre Transformationslogik von diesem Schritt unberührt zu lassen und der Engine zu ermöglichen, den Fokus zuerst auf das Ansammeln der Bestandteile zu legen. Teilen Sie dann Ihre Transformationslogik und Ihre Geschäftslogik in eigenständige Dataflows im selben Workspace auf. Verwenden Sie dazu verknüpfte oder berechnete Entitäten. Dies ermöglicht es Ihrer Engine, Ihre Berechnungen zu aktivieren und zu beschleunigen. Ihre Logik muss separat vorbereitet werden,damit die Vorteile der Compute-Engine genutzt werden können.
Stellen Sie sicher, dass Sie Operationen durchführen, die eine Zusammenführung erfordern, wie etwa Merges, Verknüpfungen, Umwandlungen und andere.
Dataflows werden entlang veröffentlichter Richtlinien und Einschränkungen erstellt.
Sie können auch DirectQuery verwenden.
Die Rechenmaschine ist eingeschaltet, aber die Leistung ist langsam.
Führen Sie die folgenden Schritte durch, wenn Sie Szenarien untersuchen, in denen die Compute-Engine aktiviert ist, die Leistung jedoch langsam ist:
Beschränken Sie berechnete und verknüpfte Entitäten, die workspaceübergreifend vorhanden sind.
Wenn Sie die erste Aktualisierung mit eingeschalteter Rechen-Engine durchführen, werden die Daten im Data Lake und im Cache gespeichert. Dieser doppelte Schreibvorgang bedeutet, dass Aktualisierungen langsamer sind.
Wenn ein Dataflow mit mehreren Dataflows verknüpft ist, sollten Sie dafür sorgen, dass Sie Aktualisierungen für die Quelldataflows so planen, dass die Aktualisierungen nicht alle zur selben Zeit durchgeführt werden.
Zugehöriger Inhalt
In den folgenden Artikeln finden Sie weitere Informationen zu Dataflows und Power BI:
- Einführung in Dataflows und Self-Service-Datenaufbereitung
- Erstellen eines Dataflows
- Konfigurieren und Verwenden eines Dataflows
- Konfigurieren des Dataflowspeichers zur Verwendung von Azure Data Lake Gen 2
- Planung der Power BI-Implementierung – Integration in andere Dienste
- Überlegungen und Einschränkungen zu Dataflows