Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieses Video und eine schrittweise exemplarische Vorgehensweise bieten eine Einführung in die Code First-Entwicklung für eine neue Datenbank. Dieses Szenario umfasst die Ausrichtung auf eine Datenbank, die nicht vorhanden ist, und Code First erstellt oder eine leere Datenbank, der Code First neue Tabellen hinzu fügt. Mit Code First können Sie Ihr Modell mithilfe von C# oder VB.Net Klassen definieren. Zusätzliche Konfiguration kann optional mithilfe von Attributen für Ihre Klassen und Eigenschaften oder mithilfe einer Fluent-API ausgeführt werden.
Sehen Sie sich das Video an
Dieses Video enthält eine Einführung in die Code First-Entwicklung für eine neue Datenbank. Dieses Szenario umfasst das Anvisieren einer nicht vorhandenen Datenbank, die von Code First erstellt wird, oder einer leeren Datenbank, zu der Code First neue Tabellen hinzufügt. Mit Code First können Sie Ihr Modell mithilfe von C# oder VB.Net Klassen definieren. Zusätzliche Konfiguration kann optional mithilfe von Attributen für Ihre Klassen und Eigenschaften oder mithilfe einer Fluent-API ausgeführt werden.
Präsentiert von: Rowan Miller
Voraussetzungen
Sie müssen mindestens Visual Studio 2010 oder Visual Studio 2012 installiert haben, um diese exemplarische Vorgehensweise abzuschließen.
Wenn Sie Visual Studio 2010 verwenden, müssen Sie auch NuGet installiert haben.
1. Erstellen der Anwendung
Um die Dinge einfach zu halten, erstellen wir eine einfache Konsolenanwendung, die Code First zum Ausführen des Datenzugriffs verwendet.
- Öffnen Sie Visual Studio.
- Datei -> Neu -> Projekt...
- Wählen Sie Im linken Menü "Windows" und "Konsolenanwendung" aus.
- Geben Sie CodeFirstNewDatabaseSample als Namen ein.
- Wählen Sie OK aus.
2. Erstellen des Modells
Definieren wir ein sehr einfaches Modell mithilfe von Klassen. Wir definieren sie einfach in der Program.cs Datei, aber in einer realen Anwendung würden Sie Ihre Klassen in separate Dateien und potenziell ein separates Projekt aufteilen.
Fügen Sie unterhalb der Programmklassendefinition in Program.cs die folgenden beiden Klassen hinzu.
public class Blog
{
public int BlogId { get; set; }
public string Name { get; set; }
public virtual List<Post> Posts { get; set; }
}
public class Post
{
public int PostId { get; set; }
public string Title { get; set; }
public string Content { get; set; }
public int BlogId { get; set; }
public virtual Blog Blog { get; set; }
}
Sie werden feststellen, dass wir die beiden Navigationseigenschaften (Blog.Posts und Post.Blog) virtuell erstellen. Dies ermöglicht das Lazy Loading-Feature von Entity Framework. Lazy Loading bedeutet, dass der Inhalt dieser Eigenschaften automatisch aus der Datenbank geladen wird, wenn Sie versuchen, darauf zuzugreifen.
3. Erstellen eines Kontexts
Jetzt ist es an der Zeit, einen abgeleiteten Kontext zu definieren, der eine Sitzung mit der Datenbank darstellt, sodass wir Daten abfragen und speichern können. Wir definieren einen Kontext, der von System.Data.Entity.DbContext abgeleitet wird und eine typierte DbSet-TEntity<> für jede Klasse in unserem Modell verfügbar macht.
Wir beginnen nun mit der Verwendung von Typen aus dem Entity Framework, daher müssen wir das EntityFramework NuGet-Paket hinzufügen.
- Projekt –> NuGet-Pakete verwalten... Hinweis: Wenn Sie nicht über die Option "NuGet-Pakete verwalten" verfügen, sollten Sie die neueste Version von NuGet installieren.
- Wählen Sie die Registerkarte "Online " aus.
- Auswählen des EntityFramework-Pakets
- Klicken Sie auf Install (Installieren).
Fügen Sie oben in Program.cs eine using-Anweisung für System.Data.Entity hinzu.
using System.Data.Entity;
Fügen Sie unter der Post-Klasse in Program.cs den folgenden abgeleiteten Kontext hinzu.
public class BloggingContext : DbContext
{
public DbSet<Blog> Blogs { get; set; }
public DbSet<Post> Posts { get; set; }
}
Hier ist eine vollständige Auflistung der elemente, die Program.cs jetzt enthalten sollen.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Data.Entity;
namespace CodeFirstNewDatabaseSample
{
class Program
{
static void Main(string[] args)
{
}
}
public class Blog
{
public int BlogId { get; set; }
public string Name { get; set; }
public virtual List<Post> Posts { get; set; }
}
public class Post
{
public int PostId { get; set; }
public string Title { get; set; }
public string Content { get; set; }
public int BlogId { get; set; }
public virtual Blog Blog { get; set; }
}
public class BloggingContext : DbContext
{
public DbSet<Blog> Blogs { get; set; }
public DbSet<Post> Posts { get; set; }
}
}
Das ist der gesamte Code, den wir zum Speichern und Abrufen von Daten benötigen. Natürlich gibt es hinter den Kulissen etwas, und wir werden uns das in einem Moment ansehen, aber zuerst sehen wir es in Aktion.
4. Lesen und Schreiben von Daten
Implementieren Sie die Main-Methode in Program.cs wie unten dargestellt. Dieser Code erstellt eine neue Instanz unseres Kontexts und fügt dann einen neuen Blog ein. Anschließend wird eine LINQ-Abfrage verwendet, um alle Blogs aus der Datenbank abzurufen, die alphabetisch nach Title sortiert sind.
class Program
{
static void Main(string[] args)
{
using (var db = new BloggingContext())
{
// Create and save a new Blog
Console.Write("Enter a name for a new Blog: ");
var name = Console.ReadLine();
var blog = new Blog { Name = name };
db.Blogs.Add(blog);
db.SaveChanges();
// Display all Blogs from the database
var query = from b in db.Blogs
orderby b.Name
select b;
Console.WriteLine("All blogs in the database:");
foreach (var item in query)
{
Console.WriteLine(item.Name);
}
Console.WriteLine("Press any key to exit...");
Console.ReadKey();
}
}
}
Sie können die Anwendung jetzt ausführen und testen.
Enter a name for a new Blog: ADO.NET Blog
All blogs in the database:
ADO.NET Blog
Press any key to exit...
Wo befinden sich meine Daten?
Standardmäßig hat DbContext eine Datenbank für Sie erstellt.
- Wenn eine lokale SQL Express-Instanz verfügbar ist (standardmäßig mit Visual Studio 2010 installiert), hat Code First die Datenbank in dieser Instanz erstellt.
- Wenn SQL Express nicht verfügbar ist, versucht Code First localDB (standardmäßig mit Visual Studio 2012 installiert) zu verwenden.
- Die Datenbank wird nach dem vollqualifizierten Namen des abgeleiteten Kontexts benannt, in unserem Fall codeFirstNewDatabaseSample.BloggingContext
Dies sind nur die Standardkonventionen, und es gibt verschiedene Möglichkeiten, die Datenbank zu ändern, die Code First verwendet. Weitere Informationen finden Sie im Thema "So ermittelt DbContext das Modell und die Datenbankverbindung" . Sie können eine Verbindung mit dieser Datenbank mithilfe des Server-Explorers in Visual Studio herstellen.
Ansicht –> Server-Explorer
Klicken Sie mit der rechten Maustaste auf Datenverbindungen , und wählen Sie "Verbindung hinzufügen" aus...
Wenn Sie im Server-Explorer noch keine Verbindung mit einer Datenbank hergestellt haben, müssen Sie Microsoft SQL Server als Datenquelle auswählen.

Herstellen einer Verbindung mit LocalDB oder SQL Express, je nachdem, welches Sie installiert haben
Wir können nun das Schema untersuchen, das Code First erstellt hat.

DbContext hat herausgearbeitet, welche Klassen in das Modell einbezogen werden sollen, indem wir die von uns definierten DbSet-Eigenschaften betrachten. Anschließend wird der Standardsatz von Code First-Konventionen verwendet, um Tabellen- und Spaltennamen zu bestimmen, Datentypen zu bestimmen, Primärschlüssel zu finden usw. Später in dieser Anleitung werden wir uns ansehen, wie Sie diese Konventionen außer Kraft setzen können.
5. Umgang mit Modelländerungen
Jetzt ist es an der Zeit, einige Änderungen am Modell vorzunehmen, wenn wir diese Änderungen vornehmen, müssen wir auch das Datenbankschema aktualisieren. Um dies zu erreichen, verwenden wir eine Funktion namens "Code First Migrationen" oder kurz "Migrationen".
Migrationen ermöglichen es uns, einen geordneten Satz von Schritten zu haben, die beschreiben, wie sie unser Datenbankschema aktualisieren (und herabstufen). Jede dieser Schritte, die als Migration bezeichnet wird, enthält code, der die anzuwendenden Änderungen beschreibt.
Der erste Schritt besteht darin, Code First Migrationen für unseren BloggingContext zu aktivieren.
Tools –> Bibliothekspaket-Manager –> Paket-Manager-Konsole
Ausführen des Befehls "Migration aktivieren" in der Paket-Manager-Konsole
Dem Projekt wurde ein neuer Migrationsordner hinzugefügt, der zwei Elemente enthält:
- Configuration.cs – Diese Datei enthält die Einstellungen, die Migrationen für die Migration von BloggingContext verwenden. Wir müssen nichts für diese exemplarische Vorgehensweise ändern, aber hier können Sie Seeddaten angeben, Anbieter für andere Datenbanken registrieren, den Namespace ändern, in dem Migrationen generiert werden usw.
- <Timestamp>_InitialCreate.cs – Dies ist Ihre erste Migration, sie stellt die Änderungen dar, die bereits auf die Datenbank angewendet wurden, um sie von einer leeren Datenbank in eine Datenbank zu nehmen, die die Tabellen "Blogs" und "Beiträge" enthält. Obwohl wir Code First diese Tabellen automatisch für uns erstellen ließen, wurden sie, nachdem wir uns für die Verwendung von Migrationen entschieden haben, in eine Migration konvertiert. Code First hat auch in unserer lokalen Datenbank verzeichnet, dass diese Migration bereits durchgeführt wurde. Der Zeitstempel für den Dateinamen wird zu Sortierungszwecken verwendet.
Nehmen wir nun eine Änderung an unserem Modell vor, fügen Sie der Blogklasse eine URL-Eigenschaft hinzu:
public class Blog
{
public int BlogId { get; set; }
public string Name { get; set; }
public string Url { get; set; }
public virtual List<Post> Posts { get; set; }
}
- Führen Sie den Befehl Add-Migration AddUrl in der Paket-Manager-Konsole aus. Der Befehl Add-Migration sucht nach Änderungen seit der letzten Migration und erstellt ein Gerüst für eine neue Migration mit allen gefundenen Änderungen. Wir können Migrationen einen Namen geben; in diesem Fall rufen wir die Migration "AddUrl" auf. Der vorbereitete Code besagt, dass wir zur dbo.Blogs-Tabelle eine URL-Spalte hinzufügen müssen, die Zeichenfolgendaten enthalten kann. Bei Bedarf konnten wir den Gerüstcode bearbeiten, in diesem Fall ist dies jedoch nicht erforderlich.
namespace CodeFirstNewDatabaseSample.Migrations
{
using System;
using System.Data.Entity.Migrations;
public partial class AddUrl : DbMigration
{
public override void Up()
{
AddColumn("dbo.Blogs", "Url", c => c.String());
}
public override void Down()
{
DropColumn("dbo.Blogs", "Url");
}
}
}
- Führen Sie den Befehl "Update-Datenbank" in der Paket-Manager-Konsole aus. Dieser Befehl wendet alle ausstehenden Migrationen auf die Datenbank an. Unsere InitialCreate-Migration wurde bereits angewendet, sodass Migrationen nur unsere neue AddUrl-Migration anwenden. Tipp: Beim Aufrufen von Update-Database können Sie die Option –Verbose verwenden, um die SQL-Anweisungen anzuzeigen, die in der Datenbank ausgeführt werden.
Die neue URL-Spalte wird nun der Tabelle "Blogs" in der Datenbank hinzugefügt:
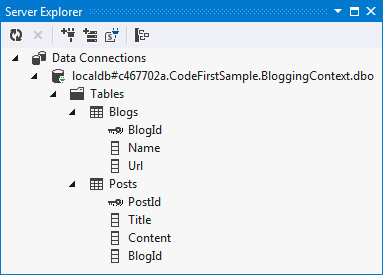
6. Datenanmerkungen
Bisher haben wir ef das Modell nur anhand seiner Standardkonventionen ermitteln lassen, aber es wird vorkommen, dass unsere Klassen nicht den Konventionen folgen und wir in der Lage sein müssen, weitere Konfigurationen durchzuführen. Hierfür gibt es zwei Optionen. In diesem Abschnitt werden wir uns die Datenanmerkungen und dann die Fluent-API im nächsten Abschnitt ansehen.
- Fügen wir unserem Modell eine Benutzerklasse hinzu
public class User
{
public string Username { get; set; }
public string DisplayName { get; set; }
}
- Außerdem müssen wir ein Set zu unserem abgeleiteten Kontext hinzufügen.
public class BloggingContext : DbContext
{
public DbSet<Blog> Blogs { get; set; }
public DbSet<Post> Posts { get; set; }
public DbSet<User> Users { get; set; }
}
- Wenn wir versucht haben, eine Migration hinzuzufügen, wird eine Fehlermeldung angezeigt, die besagt, dass "EntityType 'User' keinen Schlüssel definiert hat. Definieren Sie den Schlüssel für diesen EntityType." da EF keine Möglichkeit hat zu wissen, dass Benutzername der Primärschlüssel für Den Benutzer sein sollte.
- Wir werden jetzt Datenanmerkungen verwenden, daher müssen wir oben in Program.cs eine using-Anweisung hinzufügen.
using System.ComponentModel.DataAnnotations;
- Kommentieren Sie nun die Username-Eigenschaft, um zu identifizieren, dass sie der Primärschlüssel ist.
public class User
{
[Key]
public string Username { get; set; }
public string DisplayName { get; set; }
}
- Verwenden des Befehls "Add-Migration AddUser" zum Erstellen eines Gerüsts für eine Migration, um diese Änderungen auf die Datenbank anzuwenden
- Führen Sie den Befehl "Update-Datenbank " aus, um die neue Migration auf die Datenbank anzuwenden.
Die neue Tabelle wird nun der Datenbank hinzugefügt:
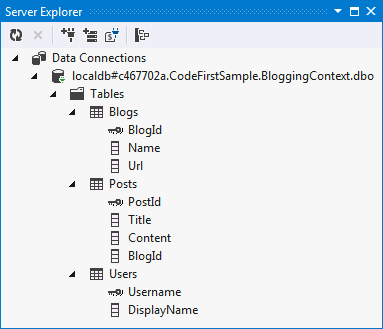
Die vollständige Liste der anmerkungen, die von EF unterstützt werden, ist:
- KeyAttribute
- StringLengthAttribute
- MaxLengthAttribute
- ConcurrencyCheckAttribute
- RequiredAttribute
- TimestampAttribute
- ComplexTypeAttribute
- Columnattribute
- Tableattribute
- InversePropertyAttribute
- ForeignKeyAttribute
- DatabaseGeneratedAttribute
- NotMappedAttribute
7. Fluent-API
Im vorherigen Abschnitt haben wir uns mit der Verwendung von Datenanmerkungen befasst, um zu ergänzen oder zu überschreiben, was durch Konvention ermittelt wurde. Die andere Möglichkeit zum Konfigurieren des Modells ist die Code First Fluent-API.
Die meisten Modellkonfigurationen können mit einfachen Datenanmerkungen durchgeführt werden. Die Fluent API ist eine fortgeschrittene Methode zur Modellkonfiguration, die alles abdeckt, was Datenanmerkungen leisten können, und bietet darüber hinaus fortgeschrittene Konfigurationsmöglichkeiten, die mit Datenanmerkungen nicht realisiert werden können. Datenanmerkungen und die Fluent-API können zusammen verwendet werden.
Um auf die Fluent-API zuzugreifen, überschreiben Sie die OnModelCreating-Methode in DbContext. Angenommen, wir wollten die Spalte umbenennen, in der User.DisplayName in display_name gespeichert ist.
- Überschreiben Sie die Methode OnModelCreating in BloggingContext mit dem folgenden Code.
public class BloggingContext : DbContext
{
public DbSet<Blog> Blogs { get; set; }
public DbSet<Post> Posts { get; set; }
public DbSet<User> Users { get; set; }
protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
modelBuilder.Entity<User>()
.Property(u => u.DisplayName)
.HasColumnName("display_name");
}
}
- Verwenden Sie den BefehlAdd-Migration ChangeDisplayName , um ein Gerüst für eine Migration zu erstellen, um diese Änderungen auf die Datenbank anzuwenden.
- Führen Sie den Befehl "Update-Datenbank " aus, um die neue Migration auf die Datenbank anzuwenden.
Die Spalte "DisplayName" wird jetzt in display_name umbenannt:

Zusammenfassung
In dieser Schritt-für-Schritt-Anleitung haben wir uns die Code First-Entwicklung anhand einer neuen Datenbank angesehen. Wir haben ein Modell mithilfe von Klassen definiert und dann dieses Modell verwendet, um eine Datenbank zu erstellen und Daten zu speichern und abzurufen. Nachdem die Datenbank erstellt wurde, haben wir Code First Migrationen verwendet, um das Schema zu ändern, während sich unser Modell weiterentwickelt hat. Außerdem haben wir erfahren, wie Sie ein Modell mithilfe von Datenanmerkungen und der Fluent-API konfigurieren.
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.