Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
In diesem Tutorial erstellen Sie mithilfe der Azure Data Factory-Benutzeroberfläche eine Pipeline, mit der Daten aus einer Azure Data Lake Storage (ADLS) Gen2-Quelle in eine ADLS Gen2-Senke kopiert und mithilfe des Zuordnungsdatenflusses transformiert werden. Das Konfigurationsmuster in diesem Tutorial kann beim Transformieren von Daten mithilfe von Mapping Data Flow erweitert werden.
Dieses Tutorial ist allgemein für die Abbildung von Datenflüssen konzipiert. Datenflüsse sind sowohl in Azure Data Factory als auch in Synapse Pipelines verfügbar. Wenn Sie mit den Datenflüssen in Azure Synapse-Pipelines noch nicht vertraut sind, lesen Sie den Artikel Datenflüsse in Azure Synapse Analytics.
In diesem Tutorial führen Sie die folgenden Schritte aus:
- Erstellen einer Data Factory
- Erstellen Sie eine Pipeline mit einer Datenfluss Aktivität.
- Erstellen eines Mapping-Datenflusses mit vier Transformationen
- Ausführen eines Testlaufs für die Pipeline
- Überwachen einer Datenfluss-Aktivität
Voraussetzungen
- Azure-Abonnement. Wenn Sie kein Azure-Abonnement haben, erstellen Sie ein free Azure Konto, bevor Sie beginnen.
- Azure Data Lake Storage Gen2 Konto. Sie verwenden den ADLS-Speicher als Quelldatenspeicher und Senkendatenspeicher. Wenn Sie nicht über ein Speicherkonto verfügen, lesen Sie Erstellen eines Azure-Speicherkontos, um die Schritte zur Erstellung eines solchen Kontos zu erfahren.
- Laden Sie MoviesDB.csv hier herunter. Um die Datei aus GitHub abzurufen, kopieren Sie den Inhalt in einen Text-Editor Ihrer Wahl, um lokal als .csv Datei zu speichern. Laden Sie die Datei in Ihr Speicherkonto in einen Container mit dem Namen "Beispieldaten" hoch.
Erstellen einer Data Factory
In diesem Schritt erstellen Sie eine Data Factory und öffnen die Data Factory-Benutzeroberfläche, um eine Pipeline in der Data Factory zu erstellen.
Öffnen Sie Microsoft Edge oder Google Chrome. Derzeit wird data Factory UI nur in den Webbrowsern Microsoft Edge und Google Chrome unterstützt.
Wählen Sie im oberen Menü die Option "Resource>Analytics>Data Factory erstellen" aus:
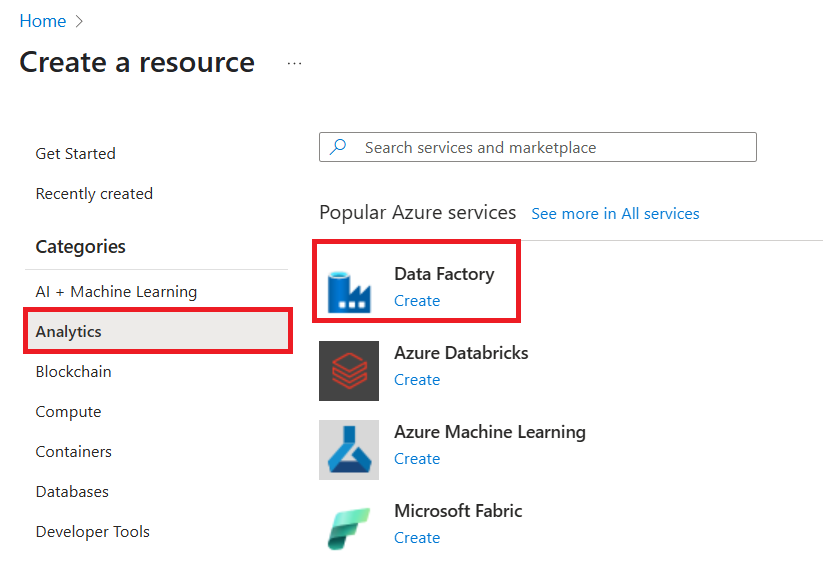
Geben Sie auf der Seite Neue Data Factory unter Name den Namen ADFTutorialDataFactory ein.
Der Name der Azure Data Factory muss globally unique sein. Wenn eine Fehlermeldung zum Namenswert angezeigt wird, geben Sie einen anderen Namen für die Data Factory ein. Beispiel: „IhrNameADFTutorialDataFactory“. Benennungsregeln für Data Factory-Artefakte finden Sie unter Data Factory-Benennungsregeln.

Wählen Sie das Azure Abonnement aus, in dem Sie die Data Factory erstellen möchten.
Führen Sie für die Ressourcengruppe eine der folgenden Schritte aus:
Wählen Sie "Vorhandene Verwenden" aus, und wählen Sie eine vorhandene Ressourcengruppe aus der Dropdownliste aus.
Wählen Sie "Neu erstellen" aus, und geben Sie den Namen einer Ressourcengruppe ein.
Weitere Informationen zu Ressourcengruppen finden Sie unter Ressourcengruppen zum Verwalten Ihrer Azure Ressourcen.
Wählen Sie unter "Version" die Option "V2" aus.
Wählen Sie unter Region einen Standort für die Data Factory aus. In der Dropdownliste werden nur unterstützte Standorte angezeigt. Datenspeicher (z. B. Azure Storage und SQL-Datenbank) und Berechnungen (z. B. Azure HDInsight), die von der Datenfactory verwendet werden, können sich in anderen Regionen befinden.
Wählen Sie "Überprüfen" und "Erstellen " und dann " Erstellen" aus.
Nach Abschluss der Erstellung wird der Hinweis im Benachrichtigungscenter angezeigt. Wählen Sie „Gehe zu Ressource“ aus, um zur Seite der Datenfabrik zu gelangen.
Wählen Sie "Studio starten" aus, um das Data Factory-Studio auf einer separaten Registerkarte zu starten.
Erstellen einer Pipeline mit einer Datenfluss-Aktivität
In diesem Schritt erstellen Sie eine Pipeline, die eine Datenfluss Aktivität enthält.
Wählen Sie auf der Startseite von Azure Data Factory Orchestrate aus.

Jetzt ist ein Fenster für eine neue Pipeline geöffnet. Geben Sie auf der Registerkarte " Allgemein " für die Pipelineeigenschaften "TransformMovies " für den Namen der Pipeline ein.
Erweitern Sie im Bereich Aktivitäten das Accordion-Element Verschieben und transformieren. Ziehen Sie die Datenfluss-Aktivität per Drag & Drop aus dem Bereich auf die Pipelinecanvas.

Benennen Sie Ihre Datenflussaktivität DataFlow1.
Setzen Sie den Schieberegler Datenfluss debuggen in der oberen Pipeline-Canvas-Leiste auf „ein“. Der Debugmodus ermöglicht das interaktive Testen von Transformationslogik mit einem aktiven Spark-Cluster. Datenfluss-Cluster benötigen 5 bis 7 Minuten zum Aufwärmen, und es wird empfohlen, dass die Benutzer zuerst das Debuggen aktivieren, wenn sie eine Datenfluss-Entwicklung durchführen möchten. Weitere Informationen finden Sie im Debugmodus.

Erstellen von Transformationslogik auf der Datenflusscanvas
In diesem Schritt erstellen Sie einen Datenfluss, der die moviesDB.csv im ADLS-Speicher nutzt, um die durchschnittliche Bewertung von Komödien aus den Jahren 1910 bis 2000 zu berechnen und zu aggregieren. Sie schreiben diese Datei dann wieder in den ADLS-Speicher.
Wechseln Sie im Bereich unterhalb des Zeichenbereichs zu den Einstellungen Ihrer Datenflussaktivität, und wählen Sie "Neu" aus, das sich neben dem Datenflussfeld befindet. Dadurch wird der Datenflussbereich geöffnet.

Benennen Sie im Eigenschaftenbereich unter "Allgemein" Den Datenfluss: TransformMovies.
Fügen Sie im Datenflussbereich eine Quelle hinzu, indem Sie das Feld "Quelle hinzufügen " auswählen.
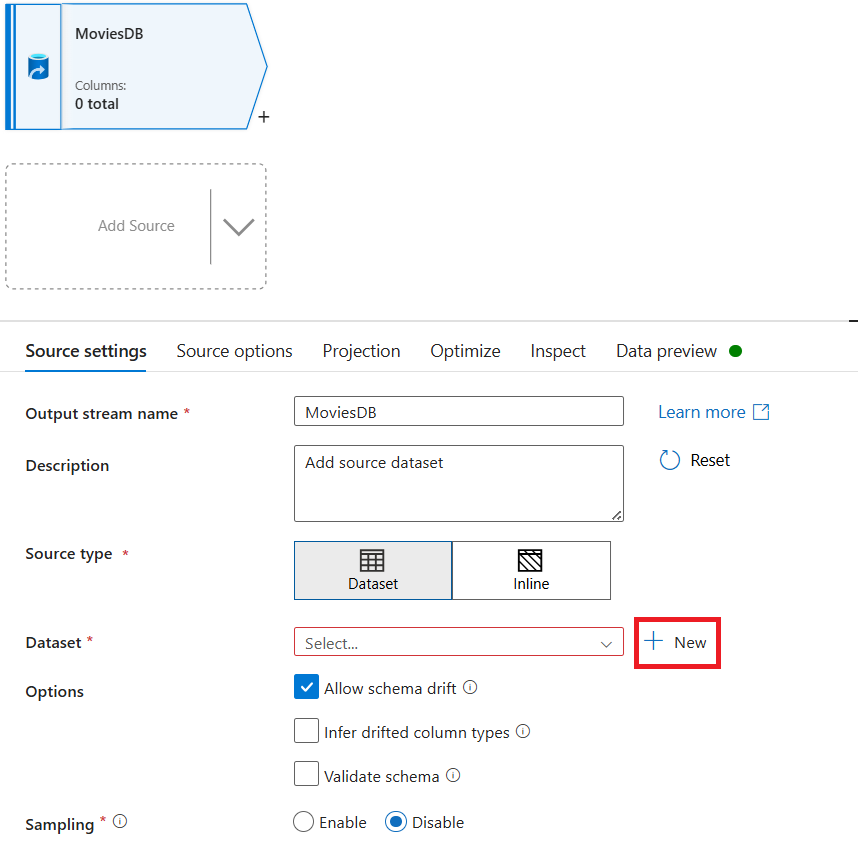
Benennen Sie Ihre Quelle MoviesDB. Wählen Sie "Neu" aus, um ein neues Quelldatenset zu erstellen.
Wählen Sie Azure Data Lake Storage Gen2 aus. Wählen Sie Weiter.

Wählen Sie "DelimitedText" aus. Wählen Sie Weiter.
Der Screenshot zeigt die Kachel "DelimitedText".
Benennen Sie Ihr Dataset MoviesDB. Wählen Sie im Dropdownmenü "Verknüpfter Dienst" die Option "Neu" aus.

Benennen Sie im Bildschirm für die Erstellung des verknüpften Diensts adLS gen2 den verknüpften Dienst ADLSGen2 , und geben Sie die Authentifizierungsmethode an. Dann geben Sie Ihre Verbindungsanmeldeinformationen ein. In diesem Tutorial wird der Kontoschlüssel zum Herstellen einer Verbindung mit dem Speicherkonto verwendet. Sie können die Testverbindung auswählen, um zu überprüfen, ob Ihre Anmeldeinformationen richtig eingegeben wurden. Wählen Sie "Erstellen" aus, wenn Sie fertig sind.

Sobald Sie sich wieder auf dem Bildschirm zum Erstellen von Datensätzen befinden, geben Sie unter dem Feld "Dateipfad " den Speicherort ihrer Datei ein. In diesem Tutorial befindet sich die Datei „moviesDB.csv“ im Container „sample-data“. Wenn die Datei Überschriften enthält, überprüfen Sie die erste Zeile als Kopfzeile. Wählen Sie "Von Verbindung/Speicher " aus, um das Headerschema direkt aus der Datei im Speicher zu importieren. Wählen Sie "OK" aus, wenn Sie fertig sind.

Wenn Ihr Debugcluster gestartet wurde, wechseln Sie zur Registerkarte "Datenvorschau " der Quelltransformation, und wählen Sie "Aktualisieren" aus, um eine Momentaufnahme der Daten abzurufen. Mithilfe der Datenvorschau können Sie überprüfen, ob die Transformation ordnungsgemäß konfiguriert ist.

Wählen Sie auf der Datenflusscanvas neben dem Quellknoten das Pluszeichen aus, um eine neue Transformation hinzuzufügen. Die erste transformation, die Sie hinzufügen, ist ein Filter.
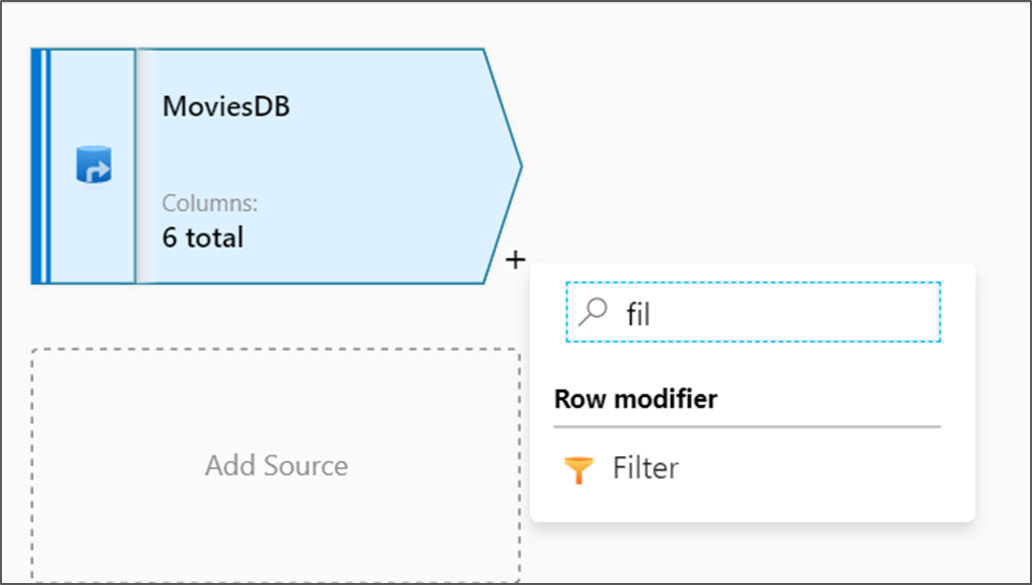
Benennen Sie die Filtertransformation FilterYears. Wählen Sie das Ausdrucksfeld neben Filtern nach aus, und dann Ausdrucks-Generator öffnen. Hier geben Sie die Filterbedingung an.

Mit dem Datenfluss-Ausdrucks-Generator können Sie Ausdrücke interaktiv erstellen, die dann in verschiedenen Transformationen verwendet werden können. Ausdrücke können integrierte Funktionen, Spalten aus dem Eingabeschema und benutzerdefinierte Parameter enthalten. Weitere Informationen zum Erstellen von Ausdrücken finden Sie unter Datenfluss Ausdrucks-Generator.
In diesem Tutorial möchten Sie Filme des Genres „Komödie“ filtern, die zwischen den Jahren 1910 und 2000 entstanden sind. Da die Jahresangabe derzeit eine Zeichenfolge ist, müssen Sie sie mithilfe der Funktion
toInteger()in eine ganze Zahl konvertieren. Verwenden Sie die Operatoren für größer als oder gleich (>=) und kleiner als oder gleich (<=) für einen Vergleich mit den Literalwerten für die Jahre 1910 und 2000. Verbinden Sie diese Ausdrücke mit dem Und-Operator (&&). Der Ausdruck sieht wie folgt aus:toInteger(year) >= 1910 && toInteger(year) <= 2000Um zu ermitteln, welche Filme Komödien sind, können Sie mithilfe der Funktion
rlike()nach dem Muster „Comedy“ in der Spalte „genres“ suchen. Vereinigen Sie den Ausdruckrlikemit dem Jahresvergleich, um Folgendes zu erhalten:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')Wenn Ein Debugcluster aktiv ist, können Sie Ihre Logik überprüfen, indem Sie "Aktualisieren" auswählen, um die Ausdrucksausgabe im Vergleich zu den verwendeten Eingaben anzuzeigen. Es gibt mehr als eine richtige Antwort darauf, wie Sie diese Logik mithilfe der Ausdruckssprache für Datenflüsse erzielen können.
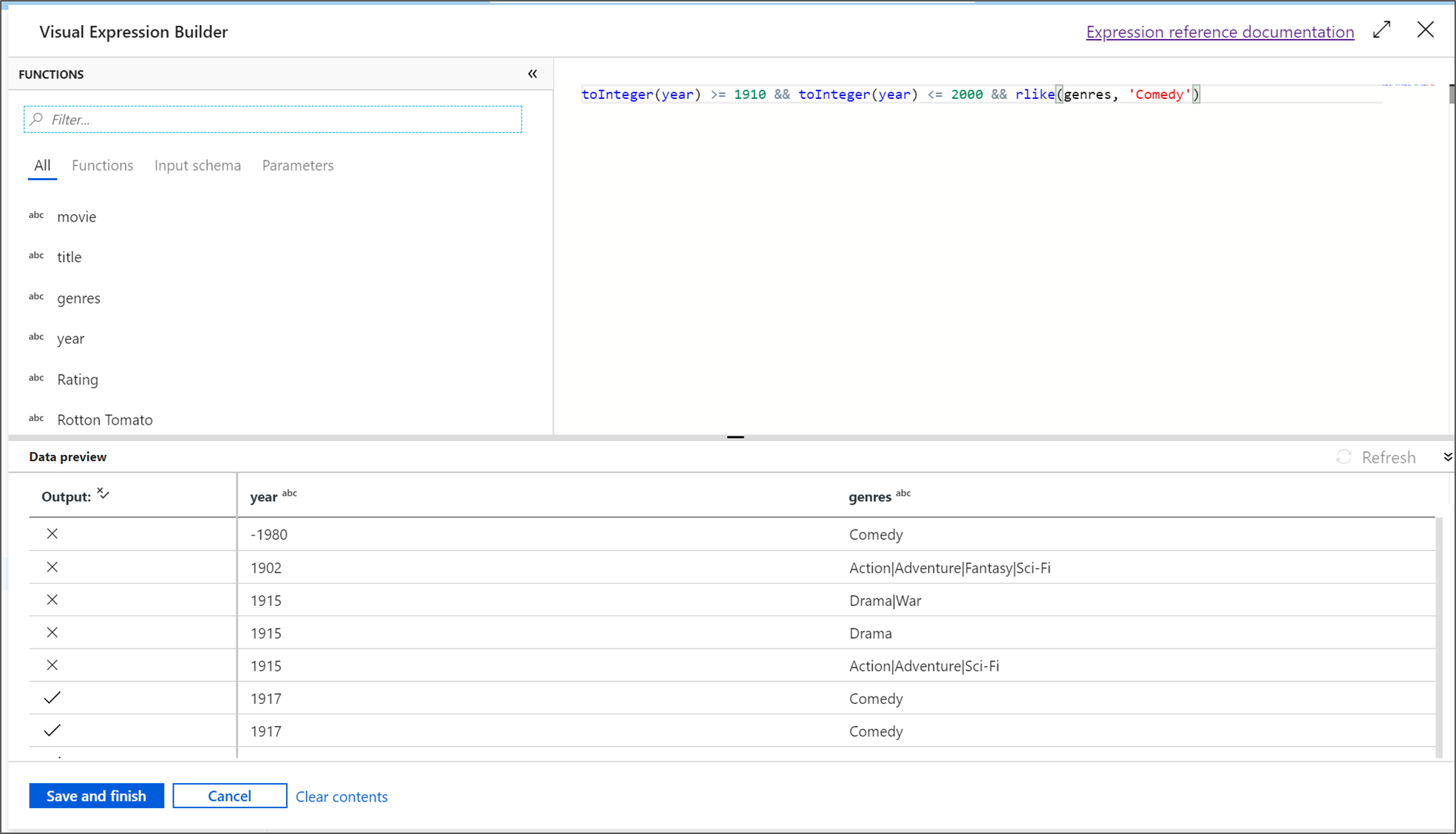
Wählen Sie "Speichern" und "Fertig stellen " aus, nachdem Sie den Ausdruck abgeschlossen haben.
Abrufen einer Datenvorschau , um sicherzustellen, dass der Filter ordnungsgemäß funktioniert.
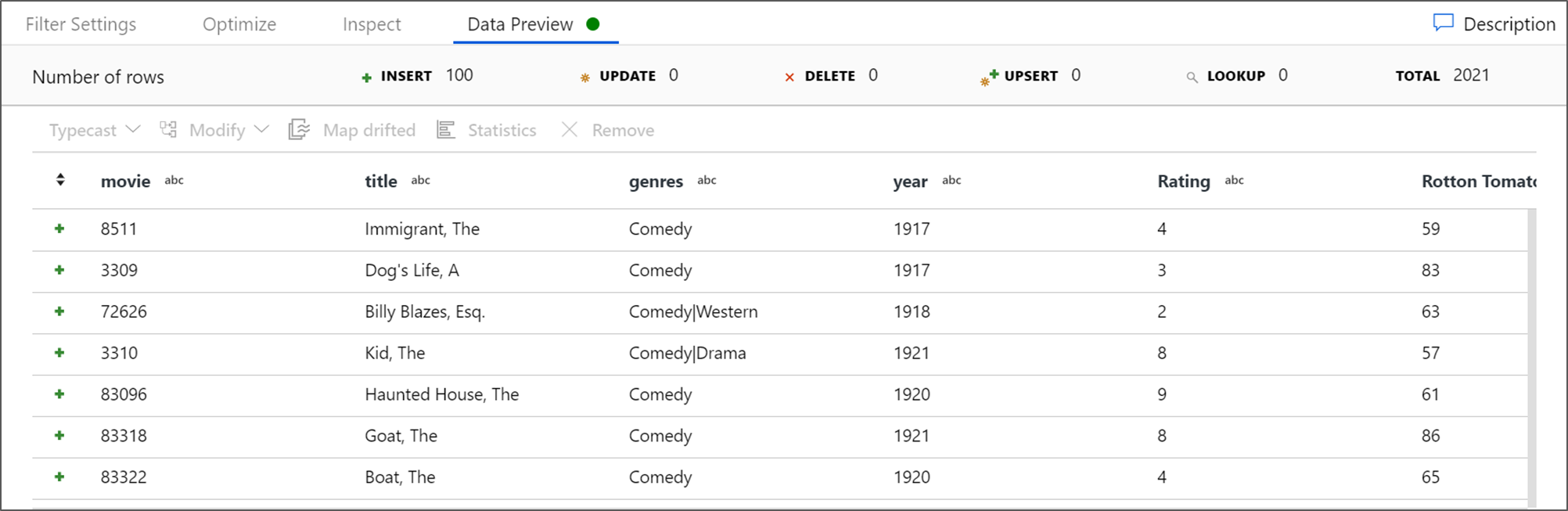
Die nächste Transformation, die Sie hinzufügen, ist eine Aggregattransformation unter Schemamodifizierer.

Benennen Sie die Aggregattransformation "AggregateComedyRatings". Wählen Sie auf der Registerkarte Gruppieren nach im Dropdown-Menü Jahr aus, um die Aggregationen nach dem Jahr zu gruppieren, in dem der Film herauskam.

Wechseln Sie zur Registerkarte "Aggregat" . Benennen Sie im linken Textfeld die Aggregatspalte AverageComedyRating. Wählen Sie das rechte Ausdrucksfeld aus, um den Aggregatausdruck über den Ausdrucks-Generator einzugeben.
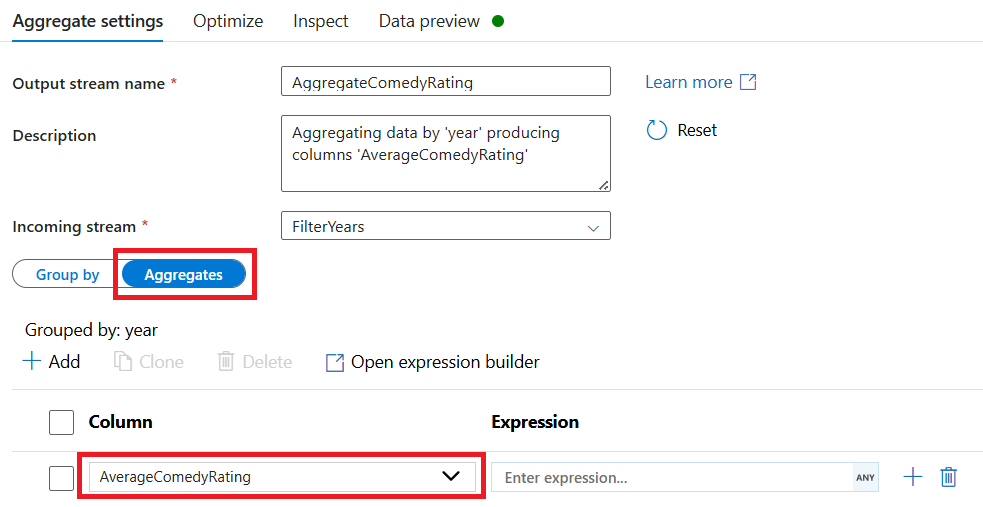
Verwenden Sie die Aggregatfunktion , um den Durchschnitt der Spalte
avg()zu erhalten. Da "Bewertung" eine Zeichenfolge ist undavg()eine numerische Eingabe einnimmt, müssen wir den Wert über dietoInteger()Funktion in eine Zahl konvertieren. Dieser Ausdruck sieht wie folgt aus:avg(toInteger(Rating))Wählen Sie "Speichern" und "Fertig stellen " aus, wenn Sie fertig sind.

Wechseln Sie zur Registerkarte "Datenvorschau ", um die Transformationsausgabe anzuzeigen. Beachten Sie, dass nur zwei Spalten vorhanden sind, Jahr und AverageComedyRating.

Als Nächstes möchten Sie eine Sinktransformation unter "Ziel" hinzufügen.
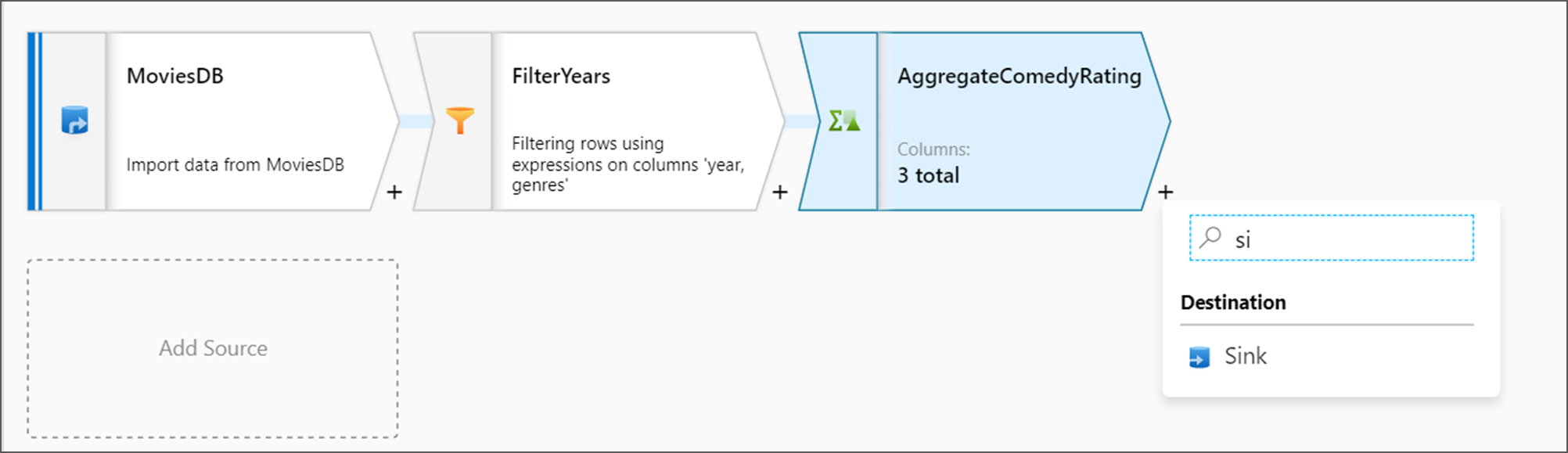
Benennen Sie Ihre Spüle Sink. Wählen Sie Neu aus, um das Senkendataset zu erstellen.

Wählen Sie Azure Data Lake Storage Gen2 aus. Wählen Sie Weiter.
Wählen Sie "DelimitedText" aus. Wählen Sie Weiter.

Geben Sie dem Senkendataset den Namen MoviesSink. Wählen Sie als verknüpften Dienst den verknüpften ADLS Gen2-Dienst aus, den Sie in Schritt 6 erstellt haben. Geben Sie einen Ausgabeordner ein, in den die Daten geschrieben werden sollen. In diesem Tutorial wird in den Ordner „output“ im Container „sample-data“ geschrieben. Der Ordner muss nicht vorab vorhanden sein und kann dynamisch erstellt werden. Setzen Sie die erste Zeile als Kopfzeile auf "true" und wählen Sie "Keine" für das Importschema aus. Wählen Sie Fertig stellen aus.

Sie haben nun die Erstellung des Datenflusses beendet. Jetzt können Sie ihn in ihrer Pipeline ausführen.
Ausführen und Überwachen des Datenflusses
Sie können eine Pipeline vor der Veröffentlichung debuggen. In diesem Schritt lösen Sie eine Debugausführung der Datenflusspipeline aus. Bei der Datenvorschau werden keine Daten geschrieben, bei einer Debugausführung werden jedoch Daten in das Senkenziel geschrieben.
Wechseln Sie zur Pipelinecanvas. Wählen Sie "Debuggen" aus, um eine Debugausführung auszulösen.
Das Pipelinedebugging von Datenfluss Aktivitäten verwendet den aktiven Debugcluster, dauert aber dennoch mindestens eine Minute, bis die Initialisierung erfolgt. Sie können den Fortschritt über die Registerkarte "Ausgabe" nachverfolgen. Sobald die Ausführung erfolgreich ist, bewegen Sie den Mauszeiger über die Ausführung und wählen Sie das Brillensymbol, um den Überwachungsbereich zu öffnen.
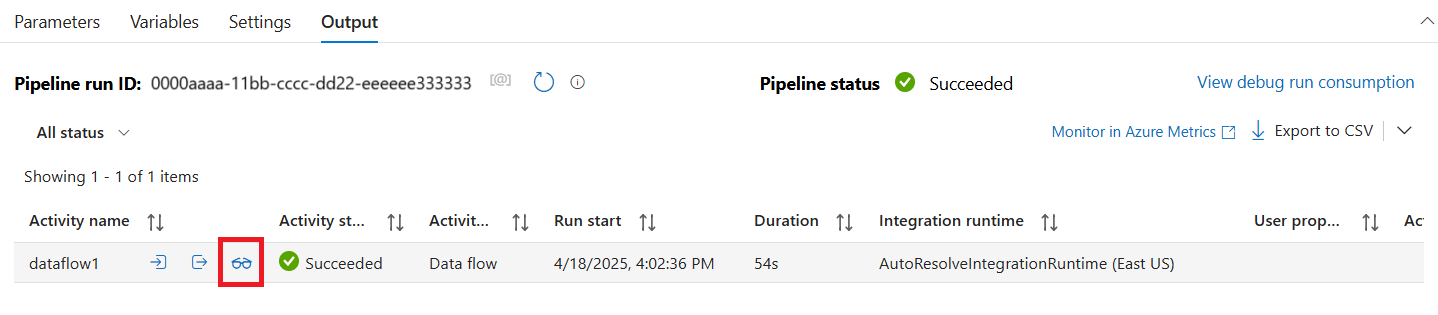
Wählen Sie im Überwachungsbereich die Schaltfläche "Phasen " aus, um die Anzahl der Zeilen und die für jeden Transformationsschritt aufgewendete Zeit anzuzeigen.


Wählen Sie eine Transformation aus, um ausführliche Informationen über die Spalten und Partitionierung der Daten zu erhalten.

Wenn Sie dieses Tutorial richtig durchgeführt haben, sollten 83 Zeilen und 2 Spalten in den Senkenordner geschrieben worden sein. Sie können sich von der Richtigkeit der Daten überzeugen, indem Sie den Blobspeicher überprüfen.
Zugehöriger Inhalt
Mit der Pipeline in diesem Tutorial wird ein Datenfluss ausgeführt, der die durchschnittliche Bewertung von Komödien zwischen 1910 und 2000 aggregiert und die Daten in ADLS schreibt. Sie haben Folgendes gelernt:
- Erstellen einer Data Factory
- Erstellen Sie eine Pipeline mit einer Datenfluss Aktivität.
- Erstellen eines Mapping-Datenflusses mit vier Transformationen
- Ausführen eines Testlaufs für die Pipeline
- Überwachen einer Datenfluss-Aktivität
Erfahren Sie mehr über die Sprache des Datenflussausdrucks.