Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Denne vejledning indsamler data i Fabric lakehouses i delta lake-format. Vi definerer nogle vigtige begreber her:
Lakehouse – Et lakehouse er en samling filer, mapper og/eller tabeller, der repræsenterer en database over en datasø. Spark-programmet og SQL-programmet bruger lakehouse-ressourcer til big data-behandling. Når du bruger Delta-formaterede tabeller med åben kildekode, omfatter denne behandling forbedrede ACID-transaktionsegenskaber.
Delta Lake – Delta Lake er et lagerlag med åben kildekode, der leverer ACID-transaktioner, skalerbar metadataadministration og batch- og streamingdatabehandling til Apache Spark. Som datatabelformat udvider Delta Lake Parquet-datafiler med en filbaseret transaktionslog for ACID-transaktioner og skalerbar metadataadministration.
Azure Open Datasets er kuraterede offentlige datasæt, der tilføjer scenariespecifikke funktioner til maskinlæringsløsninger. Dette fører til mere nøjagtige modeller. Åbne datasæt er cloud-ressourcer, der ligger på Microsoft Azure Storage. Apache Spark, REST API, Data factory og andre værktøjer kan få adgang til Open Datasets.
I dette selvstudium skal du bruge Apache Spark til at:
- Læs data fra Azure Open Datasets containere.
- Skriv data ind i en Fabric lakehouse delta-tabel.
Forudsætninger
Få et Microsoft Fabric abonnement. Eller tilmeld dig en gratis Microsoft Fabric prøveperiode.
Log ind på Microsoft Fabric.
Skift til Fabric ved at bruge experience-switcheren nederst til venstre på din startside.
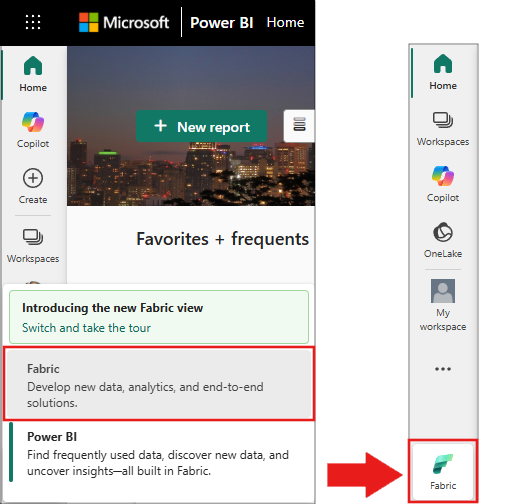
- Føj et lakehouse til denne notesbog. I dette selvstudium downloader du først data fra en offentlig blob. Derefter gemmes dataene i den pågældende lakehouse-ressource.
Bemærkning
Før du begynder, skal du sørge for at gennemføre trinnene Forbered dit system : opret et arbejdsområde, lav et søhus, og vedhæft det til din notesbog. De eksempeldata, der bruges i denne vejledning, kommer fra en offentlig container i Azure Open Datasets og tilgås programmatisk i notebook-koden.
Følg med i en notesbog
Notesbogen 1-ingest-data.ipynb følger med dette selvstudium.
Hvis du vil åbne den medfølgende notesbog til dette selvstudium, skal du følge instruktionerne i Forbered dit system til selvstudier om datavidenskab for at importere notesbogen til dit arbejdsområde.
Hvis du hellere vil kopiere og indsætte koden fra denne side, kan du oprette en ny notesbog.
Sørg for at vedhæfte et lakehouse til notesbogen , før du begynder at køre kode.
Drikkepenge
Denne vejledning læser eksempeldata fra en Azure Open Datasets container. Hvis du oplever en adgangsfejl under indlæsning af dataene, kan du manuelt downloade filen churn.csv fra fabric-samples GitHub repository og uploade den til dit lakehouse.
Bankafgangsdata
Datasættet indeholder statusoplysninger for 10.000 kunder. Den indeholder også attributter, der kan påvirke fald – f.eks.:
- Kreditscore
- Geografisk placering (Tyskland, Frankrig, Spanien)
- Køn (mand, kvinde)
- Alder
- Ansættelse (det antal år, kunden var kunde i den pågældende bank)
- Kontosaldo
- Anslået løn
- Antal produkter, som en kunde har købt via banken
- Kreditkortstatus (uanset om en kunde har et kreditkort eller ej)
- Aktiv medlemsstatus (uanset om kunden har en aktiv bankkundestatus)
Datasættet indeholder også disse kolonner:
- rækkenummer
- kunde-id
- kundens efternavn
Disse kolonner bør ikke have nogen indflydelse på en kundes beslutning om at forlade banken.
Lukningen af en debitorbankkonto definerer kundens opsigelse. Datasætkolonnen exited refererer til kundens opgivelse. Der er kun lidt kontekst om disse attributter tilgængelige, så du skal fortsætte uden baggrundsoplysninger om datasættet. Vores mål er at forstå, hvordan disse attributter bidrager til exited status.
Eksempel på rækker i datasæt:
| "Kunde-id" | "Efternavn" | "CreditScore" | "Geografi" | "Køn" | "Alder" | "Ansættelse" | "Saldo" | "NumOfProducts" | "HasCrCard" | "IsActiveMember" | "EstimatedSalary" | "Afsluttet" |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | Hargrave | 619 | Frankrig | Kvindelig | 42 | 2 | 0.00 | 0 | 0 | 0 | 101348.88 | 0 |
| 15647311 | Bakke | 608 | Spanien | Kvindelig | 41 | 0 | 83807.86 | 0 | 0 | 0 | 112542.58 | 0 |
Download datasæt, og upload til lakehouse
Drikkepenge
Når du definerer følgende parametre, kan du nemt bruge denne notesbog med forskellige datasæt:
IS_CUSTOM_DATA = False # if TRUE, dataset has to be uploaded manually
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # folder with data files
DATA_FILE = "churn.csv" # data file name
Følgende kodeuddrag downloader en offentligt tilgængelig version af datasættet og gemmer derefter denne ressource i et Fabric-lakehouse:
Vigtig
Sørg for at føje et lakehouse til notesbogen, før du kører den. Hvis du ikke gør det, resulterer det i en fejl.
import os, requests
if not IS_CUSTOM_DATA:
# Download demo data files into lakehouse if not exist
remote_url = "https://synapseaisolutionsa.z13.web.core.windows.net/data/bankcustomerchurn"
file_list = [DATA_FILE]
download_path = f"{DATA_ROOT}/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Relateret indhold
Du bruger de data, du lige har indtaget i: